
Minjia Zhang
(he/him/his)
Assistant Professor, Department of Computer Science
Affiliate Professor, Department of Electrical and Computer Engineering
University of Illinois Urbana-Champaign
Address: Thomas M. Siebel Center for Computer Science 4106, 201 North Goodwin Avenue MC 258 Urbana, IL 61801
Email: minjiaz|at|illinois|dot|edu
Prospective Ph.D./MS Students: I am actively looking for outstanding and highly-motivated students who are interested in the following research directions:
- Efficient machine learning systems (training/inference on parallel/distributed/heterogeneous hardware)
- Effective efficiency algorithms (post-training, reasoning model, model compression, etc.)
- Large-scale DL/AI applications (Agentic AI, VLM, image/video generation/understanding, etc)
About Me
I am an assistant professor (tenure-track) at the Grainger College of Engineering Computer Science of the University of Illinois Urbana-Champaign. I am affiliated with the Department of Electrical and Computer Engineering and NCSA at UIUC. I'm the Director of the Supercomputing System and AI Lab (SSAIL), where I have been very fortunate to work with students who possess exceptional motivation and skills in systems and AI. My group builds highly efficient systems for large-scale machine learning and develops systems like Universal Checkpointing, SuperOffload, X-MoE, MegaFold, SuperInfer, VecFlow, which have been published at top system and ML venues like ASPLOS, SC, USENIX ATC, MLSys, SIGMOD, ICLR, NeurIPS, ICML. Some of our techniques have also been integrated into widely used open-source frameworks, such as DeepSpeed and have been adopted in both academia and industry. Work from our lab has been featured in PyTorch Official Blog, PyTorch Conference keynote, NVIDIA GPU Technology Conference (GTC), won ASPLOS'26 Honorable Mention of Best Paper Award, SC'25 Best Student Paper Award, and ICLR'24 Honorable Mention of Outstanding Paper Award. I'm Technical Steering Committee (TSC) member of DeepSpeed project. I'm particularly excited about building next-generation AI systems for scalable and efficient intelligence, enabling new system and modeling capabilities via deep innovations, and making the technology available to everyone.
Prior to my appointment at UIUC, I had a wonderful seven years at Microsoft Research Redmond and WebXT division as a Principal Researcher and technical lead. I have had all sorts of fun of developing highly efficient and cost-effective systems and algorithms, including but not limited to: enabling and accelerating large-scale deep learning training on parallel/distributed/heterogeneous hardware (e.g., DeepSpeed-MoE, DeepSpeed-Ulysses, ZeRO-Offload), building ultra-fast inference engine (e.g., DeepSpeed-Inference, DeepCPU), model compression (e.g., ZeroQuant, XTC, FastGen), large-scale vector database (e.g., HM-ANN, iQAN, Vexless). Several of my works have been applied to Microsoft systems and products, such as Bing, Ads, Azure SQL, Windows, etc., leading to significant latency improvement and cost reduction. At Microsoft, I was an early member of DeepSpeed, an open-source deep learning optimization library that makes training and inference DL models easy, efficient, and effective. DeepSpeed has enabled the training of some of the largest language models in the world, such as Megatron-Turing 530B. It has been widely adopted by both the industry and academia and has become a common backend for various popular DL frameworks such as HuggingFace, PyTorch Lightning, Fairscale, etc. I was also the co-chair of the engineering/scaling group of the BigScience project, contributing to the training of the BLOOM 176B model, which was the world's largest open multilingual language model. Before DeepSpeed, I drove the DeepCPU project at Microsoft, a DL inference optimization library that brought order-of-magnitude latency and cost reduction to mission-critical production DL models. Before joining Microsoft, I finished my Ph.D. from the Computer Science Department at Ohio State University in May 2016, where I was a member of the PLaSS group working on building efficient and scalable systems with strong semantics for parallel programs and advised by Prof. Michael D. Bond. Along the way, I spent the summer/fall of 2015, the summer of 2016 at Microsoft Research Redmond, working with Kathryn McKinley, Sameh Elnikety, and Yuxiong He. I have been serving as area chair of NeurIPS and ICLR, program committee member for ASPLOS, USENIX ATC, SIGCOMM, MLSys, IPDPS, AAAI, and reviewers for ICLR, ICML, CVPR, ICCV, ECCV, ECAI, VLDB, etc. I co-organized tutorials and workshops, such as "Mixture-of-Experts in the Era of LLMs: A New Odyssey" at ICML 2024, and "Building Efficient Large-Scale Model Systems with DeepSpeed: From Open-Source Foundations to Emerging Research" at ASPLOS 2026. I have received several awards including the Distinguished Paper Award and Distinguished Artifact Award in OOPSLA 2015, Microsoft Excellence Awards, the Honorable Mention of the ICLR 2024 Outstanding Paper Award, NSF CAREER Award, Google ML and Systems Junior Faculty Award 2025 for building highly efficient ML systems, Amazon Research Award, and UIUC Dean's Award for Excellence in Research.-
Recent News
- [7/28/2026] Will serve as the SC'26 AI4S Workshop Committee.
- [7/27/2026] Will serve as the Senior Program Committee for AAAI 2027.
- [7/8/2026] Our paper Universal Attention has been accepted at CoLM'26. 854 of 2939 submissions were accepted. Congratulations to Haochen, Ahan, and our collaborators!
- [7/2/2026] Our paper ELMoE has been conditionally accepted at SC'26. Only 146 of 769 submissions were accepted. Congratulations to Zixian, Liheng, Sajal, Emily, and Feiyi!
- [6/14/2026] Will serve as the PC at HPCA'27. Thank you, Paul V. Gratz and Nael Abu-Ghazaleh, for the invitation!
- [4/30/2026] PuzzleMoE has been accepted at ICML 2026! Congratulations Yushu and Zheng.
- [4/6/2026] Excited to share that our group has 4 papers accepted at ACL 2026, including long-horizon agent planning, hallucination detection, test-time scaling, and multi-modal generation!
- [4/4/2026] Will serve as the HPC for Machine Learning Committee at SC'26. Thank you, Rio Yokota, for the invitation!
- [3/25/2026] Will serve as an Associate Editor for the Editorial Board of ACM Computing Surveys. Thank you, Hanghang, for the invitation!
- [3/24/2026] Will serve as the area chair of NeurIPS'26.
- [3/18/2026] Both MegaFold and VoltanaLLM have been accepted at ISC 2026. Congratulations everyone!
- [3/18/2026] Our paper SuperOffload has been selected as a Best Paper Award candidate (top 16 / 1029 submissions) at ASPLOS 2026.
- [3/5/2026] I'm honored to receive the Dean's Award for Excellence in Research 2026.
- [3/5/2026] Will serve as a member of the 34th ACM Multimedia 2026 Program Committee.
- [3/2/2026] Xinyu Lian from SSAIL Lab won the 2026 Microsoft Research Fellowship. Congratulations, Xinyu!
- [2/25/2026] Will serve as the PC of ICCP'26. Thanks, Giulia Guidi, for the invitation!
- [1/26/2026] SuperInfer has been accepted at MLSys'26! Congratulations, Jiahuan, Mingtao, and Zichao!
- [1/26/2026] 4 papers have been accepted at ICLR'26, ranging from long context extension, automated sequence parallelism, lookahead GRPO optimization, and agentic AI tool using! Congratulations to all students and collaborators.
- [1/15/2026] Will serve as the TPC of ICDCS 2026. Thank you, Dong Wang, for the invitation!
- [11/24/2025] The "VecFlow-Chamfer: A GPU-based Data Management System for High-Performance Multi-Vector Search on Superchips" has been accepted at SIGMOD'26. Congratulations, Chenghao, Ben, and Philip!
- [11/20/2025] X-MoE just won the SC 2025 Best Student Paper Award!
- [11/7/2025] The "Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning" paper has been accepted at AAAI 2026. Congratulations, everyone!
- [9/22/2025] The "Aha Moment Revisited: Are Vision Language Models Truly Capable of Self-verification in Inference Scaling?" paper has been accepted at NeurIPS 2025 Multimodal Algorithmic Reasoning workshop. Congratulations, everyone!
- [9/15/2025] I'm grateful to be included on the Teachers Ranked as Excellent by Their Students list for the inaugural offering of CS 498 Machine Learning Systems at UIUC in Spring 2025.
- [9/4/2025] I'm honored to be selected to receive the Amazon Research Award. Thank you, Amazon!
- [8/20/2025] Both LACING (effective VLM training) and Cache-of-Thought (VLM cascading) have been accepted at EMNLP Main Conference 2025! Congratulations, everyone!
- [8/16/2025] I will serve as Area Chair of ICLR 2026.
- [8/14/2025] Gave an invited talk to AMD on MegaFold, our system optimization library for accelerating AlphaFold3 training.
- [7/31/2025] Gave two talks on MoE and AlphaFold3 training at TPC 2025.
- [7/14/2025] The work "NetZIP: Algorithm/Hardware Co-design of In-network Lossless Compression for Distributed Large Model Training" has been accepted at MICRO'25. 120 of 597 submissions accepted. Congratulations, Jinghan and Nam Sung!
- [7/9/2025] I'm invited to give two talks at Trillion Parameter Consortium (TPC)'25 about system-level optimizations for accelerating protein structure prediction models and emerging MoEs.
- [7/4/2025] SSAIL Lab's work FlexGaussian, which enables flexible and efficient compression of 3D Gaussian Splatting models, has been accepted at ACM MM 2025 (Oral). Congratulations, Boyuan, Eddie, Jacob, and Xiaotong!
- [6/30/2025] Will serve as the Sponsorship Chair of HPCA'26. Thanks, Leon, for the invitation!
- [6/26/2025] SSAIL Lab's work X-MoE, which enables efficient and cross-platform training of emerging expert-specialized MoE models such as DeepSeek-MoE, has been accepted at SC 2025. Only 136 of 643 submissions were accepted. Congratulations, Yueming, Ahan, Jianping, Sajal, and Feiyi!
- [6/25/2025] SSAIL Lab's work SuperOffload, which enables efficient and cost-effective training of LLMs on Superchips, has been accepted at ASPLOS 2026. Only 20 of 208 submissions were accepted. Congratulations, Xinyu, Masahiro, and Tunji!
- [6/25/2025] SSAIL Lab's work, InstantEdit, which enables efficient text-guided image editing, has been accepted at ICCV 2025. Congratulations, Nick and Zhen!
- [6/20/2025] I'm honored to be selected to receive the inaugural 2025 Google ML and Systems Junior Faculty Award. Thank you, Google!
- [6/5/2025] Will serve as the PC of SoCC'25. Thanks, Ryan and Ram, for the invitation!
- [5/23/2025] SSAIL lab's work VecFlow has been accepted at SIGMOD 2025! Congratulations, Jingyi, Chenghao, and Ben!
- [5/15/2025] Both MiniKV and MedCite have been accepted at ACL Finding 2025! Congratulations, everyone!
- [5/10/2025] Will serve as the PC of the 4th Workshop on Practical Adoption Challenges of ML for Systems (PACMI'25). Thanks, Francis, for the invitation!
- [4/25/2025] Our work on universal checkpointing for large-scale reconfigurable parallelism has been accepted at USENIX ATC 2025. 100 out of 634 submissions were accepted. Congratulations, Xinyu, Masahiro, Sam, Lev, Stas, and Tunji!
- [4/10/2025] Gave a lightning talk at IIDAI Annual Meeting on long context extension of hybrid models.
- [3/1/2025] Will serve as the session chair of the large language model track at PPoPP 2025.
- [2/26/2025] The work "Toward Sensor-In-the-Loop LLM Agent: Benchmarks and Implications" has been accepted at SenSys 2025!
- [2/17/2025] Will serve as the Area Chair of NeurIPS'2025.
- [2/12/2025] Gave a talk on ``Towards Efficient and Scalable Systems for Training Large-Scale AI-based Scientific Models" at AMD-Xilinx Heterogeneous Compute Cluster (HACC) Seminar.
- [2/11/2025] SSAIL Lab's work on compressing MoE models, including DeepSeek-MoE, has been accepted at MLSys 2025. Congratulations, Beichen, Yueming, and Zelei!
- [2/3/2025] DeepSpeed has officially become a Linux Foundation AI & Data project! Let's advance open-source AI together!
- [2/3/2025] SSAIL member Xinyu Lian received the Amazon PhD Fellowship! Congratulations, Xinyu, and thank you, Amazon!
- [12/31/2024] Honored to receive the NSF CAREER award, which will support our work on powering the next-generation AI models!
- [11/2/2024] Two papers have been accepted at HPCA 2025! Buffalo is a system that enables large-scale GNN training through efficient bucketization, and VQ-LLM enables high-performance vector quantization for LLM inference!
- [9/26/2024] Our work "UltraEdit: Instruction-based Fine-Grained Image Editing at Scale" has been accepted at NeurIPS D&B Track 2024!
- [9/11/2024] Our work on "Improving Retrieval-Augmented Generation in Medicine with Iterative Follow-up Questions" has been accepted at the Pacific Synposium on Biocomputing 2025. Congratulations everyone!
- [9/10/2024] I am honored to serve as both the PC and Artifact Evaluation Chair for MLSys'2025.
- [8/13/2024] Will serve as the reviewer of ICLR'2025.
- [8/11/2024] Will serve as the PC of IPDPS'2025.
- [8/5/2024] Will serve as the ERC of PPoPP'2025.
- [7/22/2024] Gave a tutorial and served as the panelist of "Mixture-of-Experts in the Era of LLMs A New Odyssey" at ICML'2024 in Vienna, Austria.
- [7/5/2024] Our paper "Large Language Models as Configuration Validators" has been accepted at ICSE 2025. Congratulations to Xinyu, Yinfang, and Tianyin!
- [7/3/2024] Will serve as the program committee for the 1st Unlearning and Model Editing (U&Me'24) workshop at ECCV 2024.
- [7/1/2024] Universal Checkpointing has been released in DeepSpeed! [中文] [日本語]
- [6/30/2024] Will be serving as a TPC member of MLSys 2025.
- [6/21/2024] Gave a talk on "Towards Efficient System and Algorithm for Large-Scale Scientific Discovery" at the European Trillion Parameter Consortium (TPC) Kickoff workshop in Barcelona.
- [6/10/2024] Will be serving as Program Committee for AAAI 2025.
- [5/7/2024] The "Model Tells You What to Discard" paper received the honorable mention of the ICLR 2024 Outstanding Paper Awards.
- [5/5/2024] Our work on enabling training of massive sequence transformer models has been accepted at the 43rd ACM Symposium on Principles of Distributed Computing (PODC 2024)!
- [4/29/2024] I am invited to give a talk on large-scale training at the European Trillion Parameter Consortium (TPC) Kickoff workshop in Barcelona in June.
- [4/5/2024] Our tutorial of "Mixture-of-Experts in the Era of LLMs: A New Odyssey" has been accepted by ICML 2024!
- [3/27/2024] Will be serving as the area chair for NeurIPS 2024.
- [3/10/2024] Our work on serving vector database with serverless functions has been accepted at SIGMOD 2024!
- [2/29/2024] OpenFold has been accepted in principle at Nature Methods!
- [2/13/2024] Will be serving as the reviewer of the first Conference on Language Modeling (CoLM).
- [2/2/2024] Will be serving in the Review Board for PVLDB from April 2024 through March 2025.
- [1/17/2024] Will be serving as a reviewer for ECCV 2024.
- [1/16/2024] Our paper on enabling profiling-based adaptive KV cache optimization for LLM inference has been accepted as at ICLR 2024 for oral presentation! The acceptance rate for oral this year is 1.2%.
- [12/27/2023] Will be serving as a PC for USENIX ATC 2024.
- [12/16/2023] I will be serving as a panelist at the 3rd Efficient Natural Language and Speech Processing (ENLSP) workshop at NeurIPS 2023, New Orleans. Thank you Yu, Yue, Medhi, and Soheila for the invitation!
- [12/9/2023] Our paper on enabling efficient DNN training via data efficient optimizations has been accepted at AAAI 2024!
- [12/7/2023] Our paper on enabling efficient DNN training on preemptible instances has been accepted at NSDI 2024! Congrats everyone!
- [12/27/2023] Will be serving as a reviewer for ICML 2024.
- [10/30/2023] Will be serving as a reviewer for CVPR 2024.
- [9/8/2023] Will be serving as a reviewer for MLSys 2024.
- [8/24/2023] Will be serving as a reviewer for ICLR 2024.
- [8/15/2023] Our paper on cost-effective on-device continual learning has been accepted at MobiCom 2023!
- [7/15/2023] Our paper on adversarial fine-tuning efficiency optimizations has been accepted at ECAI 2023!
- [3/21/2023] Will be serving as a PC for ASPLOS 2024.
- [2/6/2023] Will be serving as a reviewer for ICCV 2023.
- [1/21/2023] Our paper on compressed communication for large-scale training 0/1 Adam has been accepted at ICLR 2023!
- [11/7/2022] Our paper on fast and accurate vector search via intra-query parallelism has been accepted at PPoPP 2023!
- [9/20/2022] Our paper on large-scale GNN training on a single-node machine has been accepted at ASPLOS 2023!
- [9/14/2022] Three papers have been accepted at NeurIPS 2022! 2665 out of 10411 submissions are accepted.
- [7/8/2022] Our paper on large-scale DNN training on spot instances has been accepted at NSDI 2023! 50 out of 272 submissions are accepted.
- [6/13/2022] Our paper on large-scale inference for Transformer models has been accepted at SC 2022! 81 out of 320 submissions are accepted.
- [5/18/2022] Will be serving as a reviewer for ECAI 2023.
- [05/5/2022] Our paper on advancing the next generation of AI via Mixture-of-Experts has been accepted at ICML 2022! 1117 out of 5630 submissions are accepted.
- [2/24/2022] Our paper on continual learning has been accepted at DAC 2022!
- [12/1/2021] Our paper on adversarial data augmentation for knowledge distillation has been accepted at AAAI 2022! 1349 out of 9251 submissions are accepted.
- [10/11/2021] Our paper on graph sampling and pruning for nearest neighbor search has been accepted at WSDM 2022! 159 out of 786 submissions are accepted.
- [9/28/2021] Our paper on semi-structured sparsity for compressing Transformer networks has been accepted at NeurIPS 2021.
Research Interests and Selected Publications
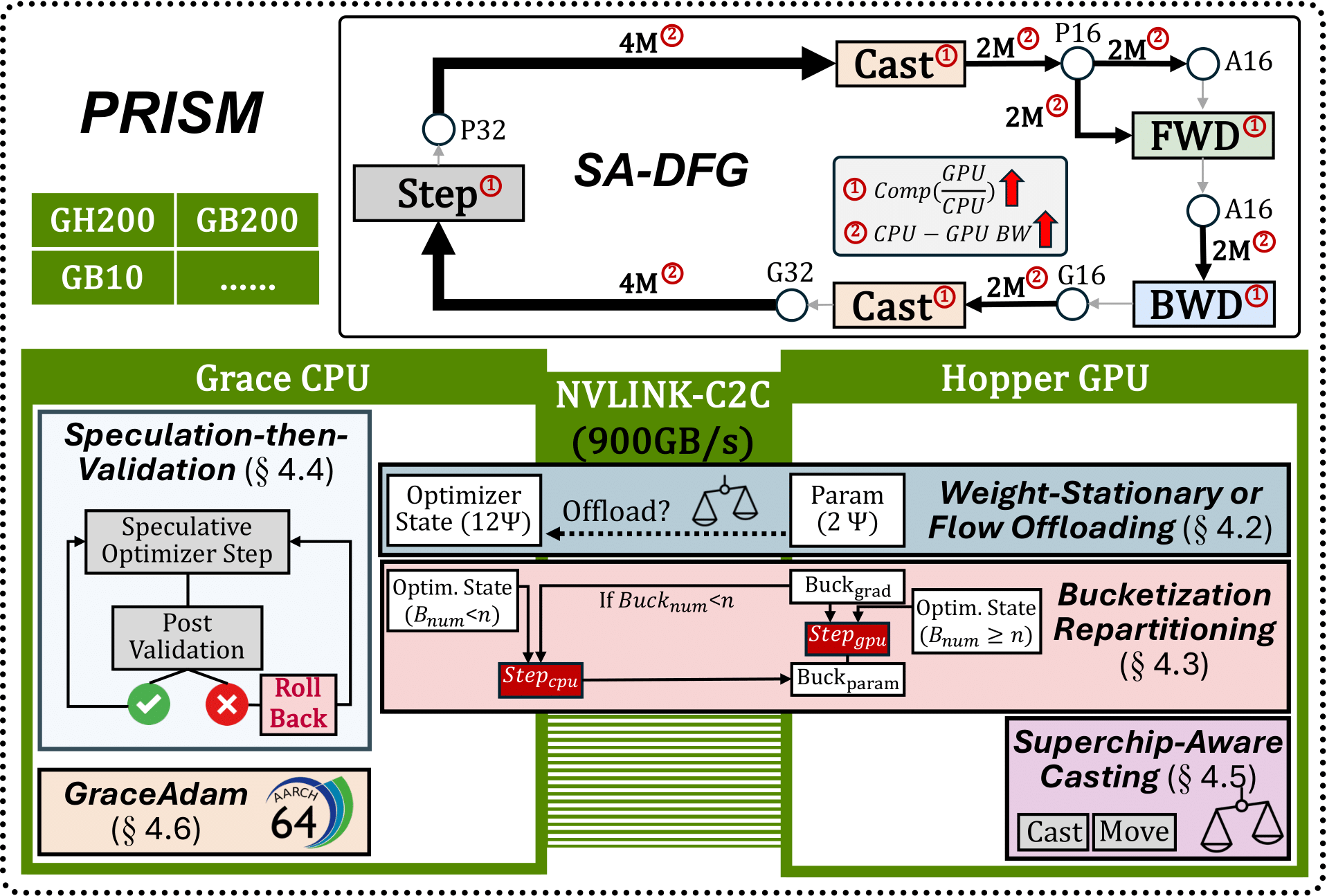 |
SuperOffload: Unleashing the Power of Large-Scale LLM Training on Superchips
ASPLOS 2026 (Honorable Mention of the Best Paper Award)
[Project Page]
Enabled 4X throughput improvement over SoTA, up to 25B model on a single GH200, and 1 million sequence length training on 8 GH200 while achieving 55% MFU. Featured by PyTorch Official Blog Presented at PyTorch Conference 2025 as part of keynote and technical session |
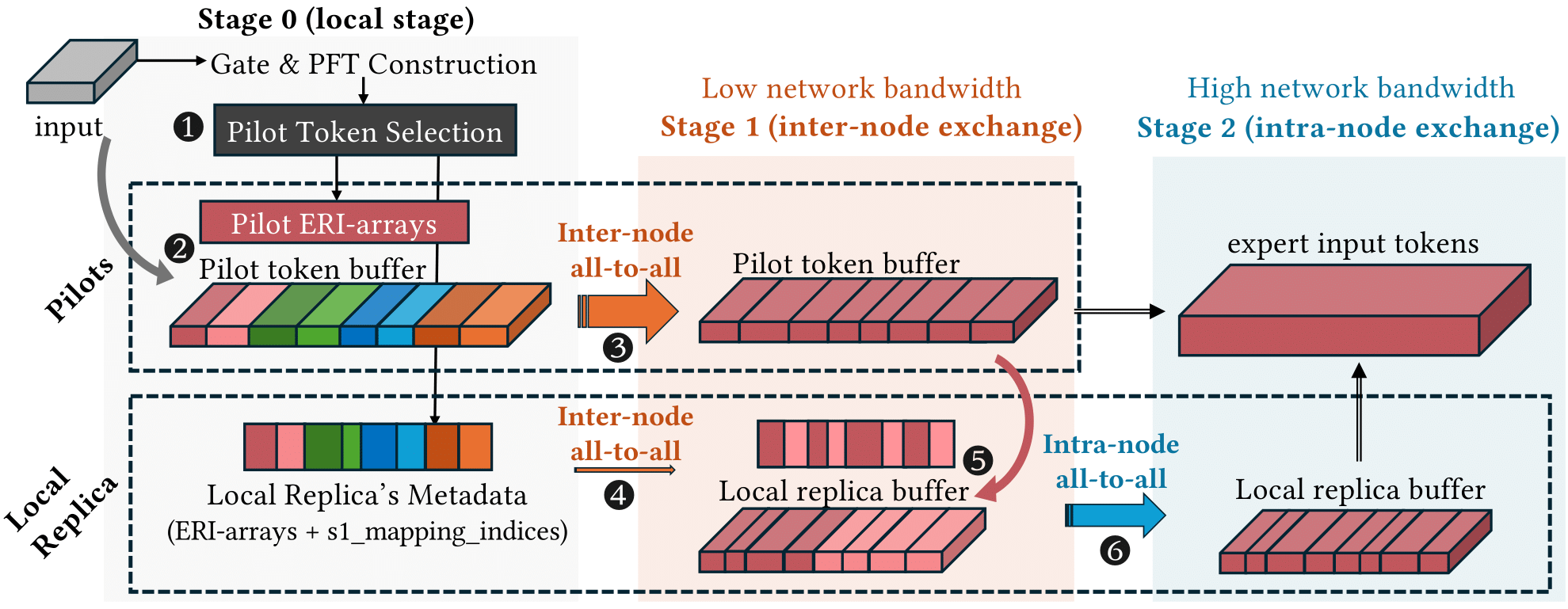 |
X-MoE: Enabling Scalable Training for Emerging Mixture-of-Experts Architectures on HPC Platforms
SC 2025 Best Student Paper Award [Project Page] Enabled DeepSeek-style MoEs training with up to 545 billion parameters across 1024 AMD GPUs, 10x larger than the largest trainable model with existing methods under the same hardware budget, while maintaining high training throughput. |
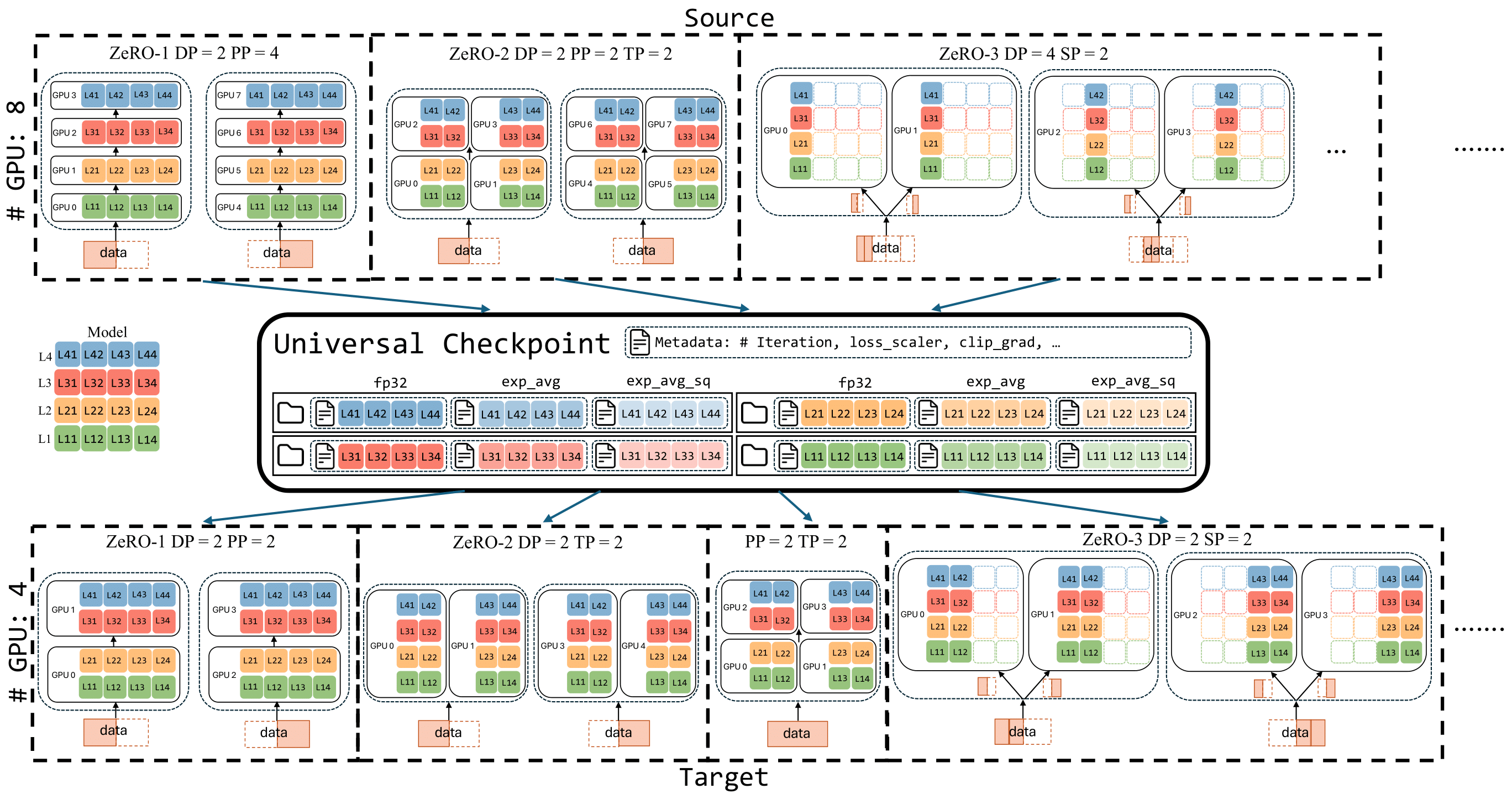 |
USENIX ATC 2025 [Project Page] Adopted by Microsoft Phi-3.5-MoE-42B (1.3M downloads), BigScience BLOOM-176B (5.0M downloads), Argonne National Laboratory (AuroraGPT), Oak Ridge National Laboratory, and many more for resilient training Validated in cluster with 1,000+ GPUs across both NVIDIA and AMD platforms Invited for Presentation at PyTorch Day 2025, FMS 2025, SDC 2025 |
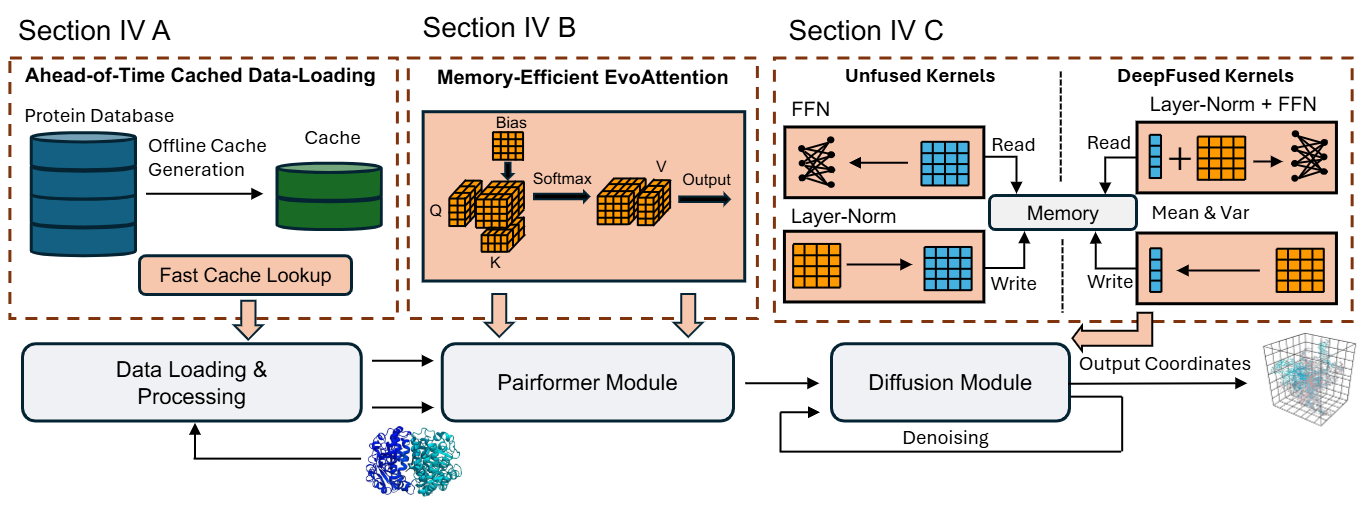 |
MegaFold: Efficient Training of Next-Generation 3D-Attention Protein Models on Cross-Platform GPUs
ISC 2026 [Project Page] MegaFold's optimizations have been adopted and extended in systems such as OpenFold3 [AMD Blog] |
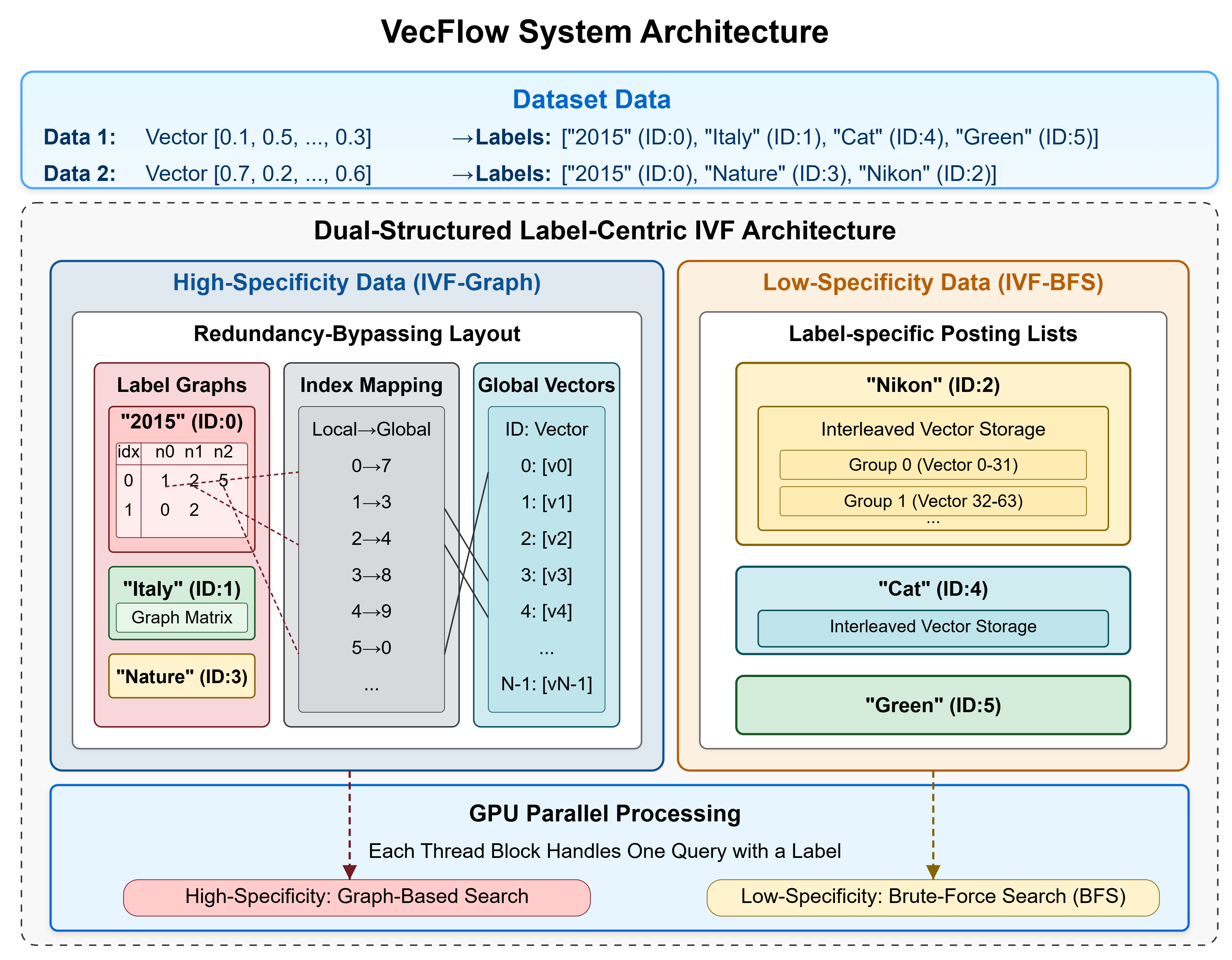 |
SIGMOD 2026 R1 (VecFlow), SIGMOD 2026 R3 (VecFlow-Chamfer) [Project Page] The first GPU-accelerated filter-based and multi-vector search system, delivering up to 100X higher throughput than state-of-the-arts CPU-based solutions! Received a honorable mention in NVIDIA's GTC 2025 talk on GPU-accelerated vector search |
AI Training at Scale and Speed: Breaking the Memory Wall and Beyond
|
SuperOffload: Unleashing the Power of Large-Scale LLM Training on Superchips
ASPLOS 2026 (Honorable Mention of the Best Paper Award)
[Project Page]
Enabled 4X throughput improvement over SoTA, up to 25B model on a single GH200, and 1 million sequence length training on 8 GH200 while achieving 55% MFU. Featured by PyTorch Official Blog Presented at PyTorch Conference 2025 as part of keynote and technical session |
|
MegaFold: Efficient Training of Next-Generation 3D-Attention Protein Models on Cross-Platform GPUs
ISC 2026 [Project Page] The MegaFold Triton kernels for EvoFormer-style operations have been adopted and extended in systems such as OpenFold3 [AMD Blog] |
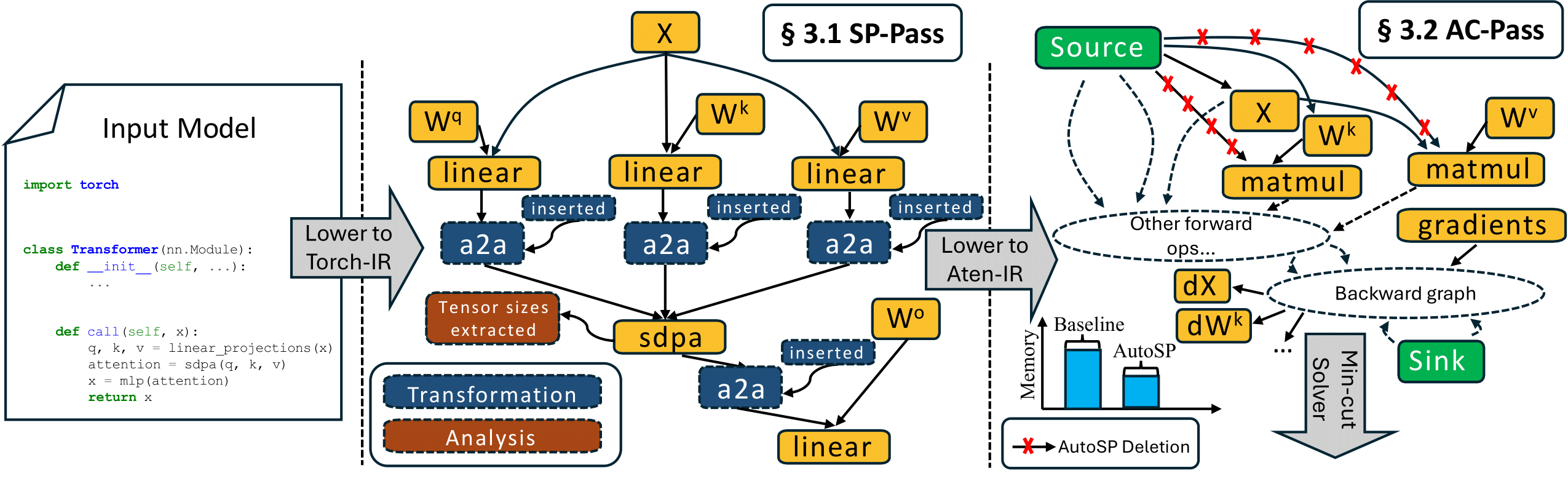 |
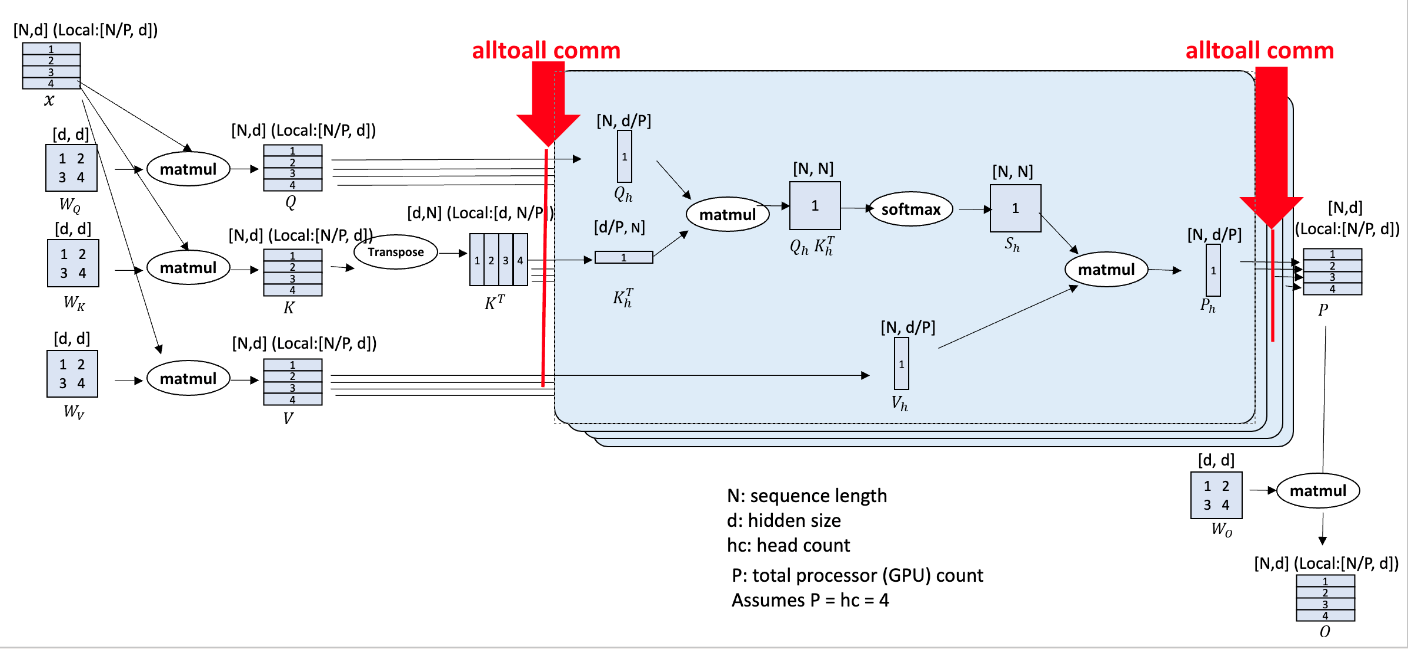
AutoSP: Unlocking Long-Context LLM Training Via Compiler-Based Sequence Parallelism
ICLR 2026 [Project Page] Featured by PyTorch Official Blog |
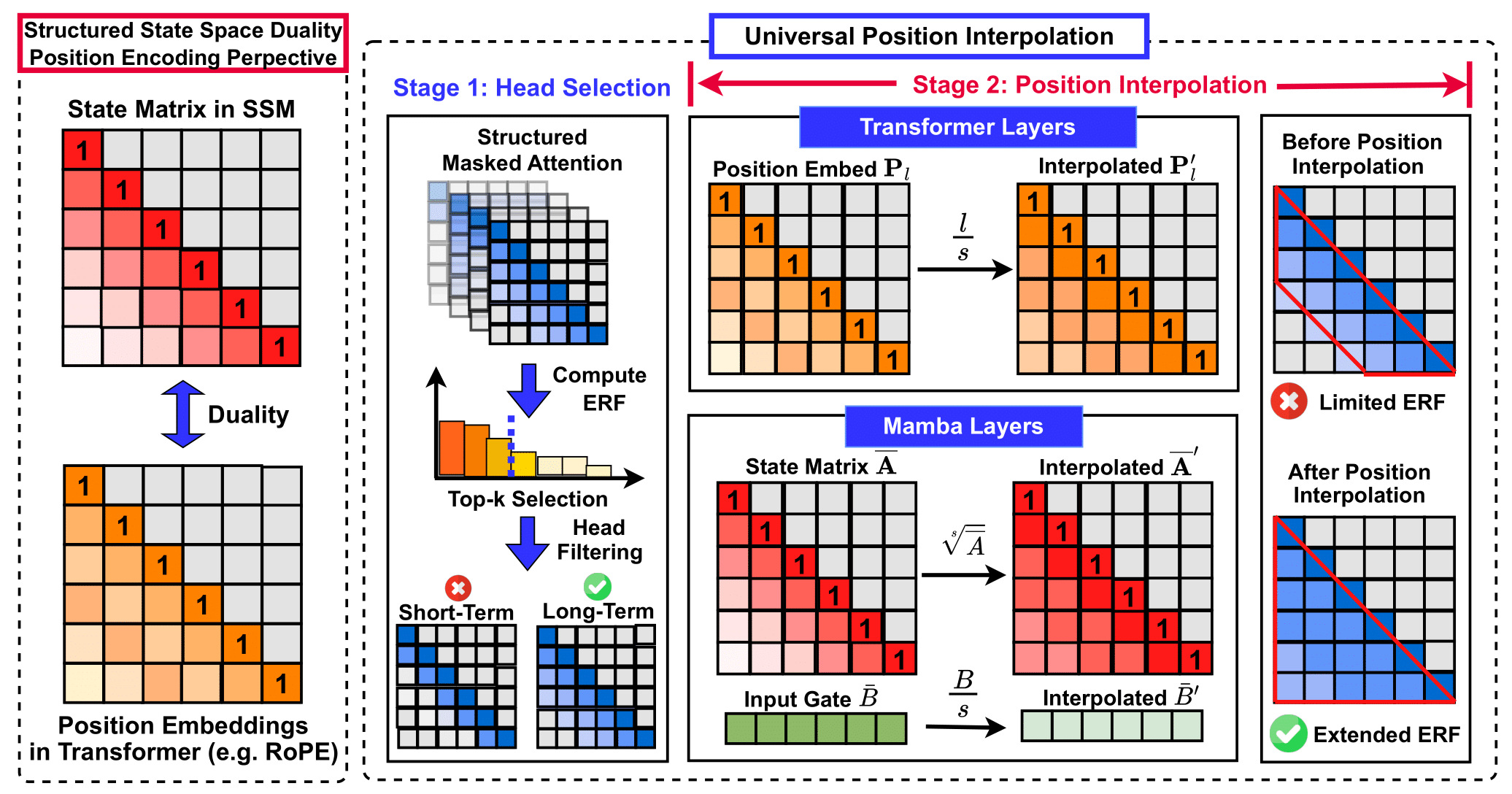 |
ICLR 2026 [Project Page] |
|
X-MoE: Enabling Scalable Training for Emerging Mixture-of-Experts Architectures on HPC Platforms
SC 2025 (Best Student Paper Award) [Project Page] Enabled DeepSeek-style MoEs training with up to 545 billion parameters across 1024 AMD GPUs, 10x larger than the largest trainable model with existing methods under the same hardware budget, while maintaining high training throughput. |
|
USENIX ATC 2025 [Project Page] Adopted by Microsoft Phi-3.5-MoE-42B, BigScience BLOOM-176B, and many more for resilient training |
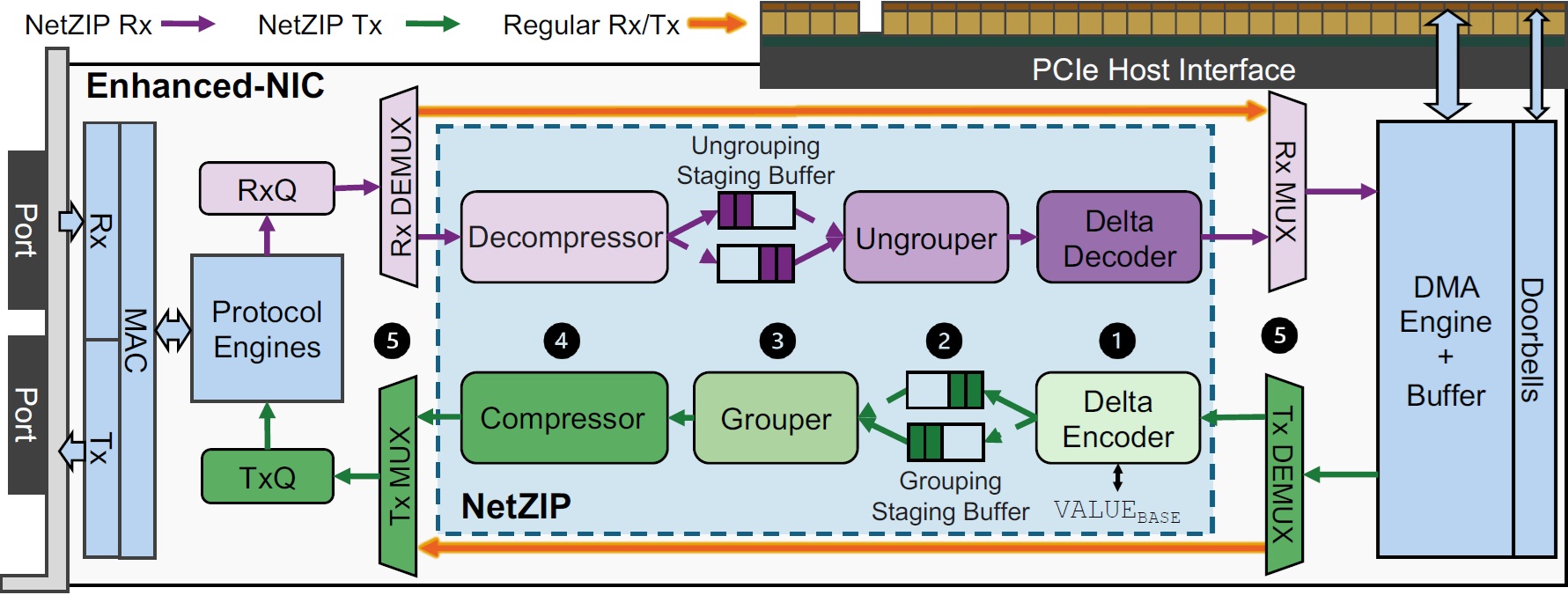 |
MICRO 2025 |
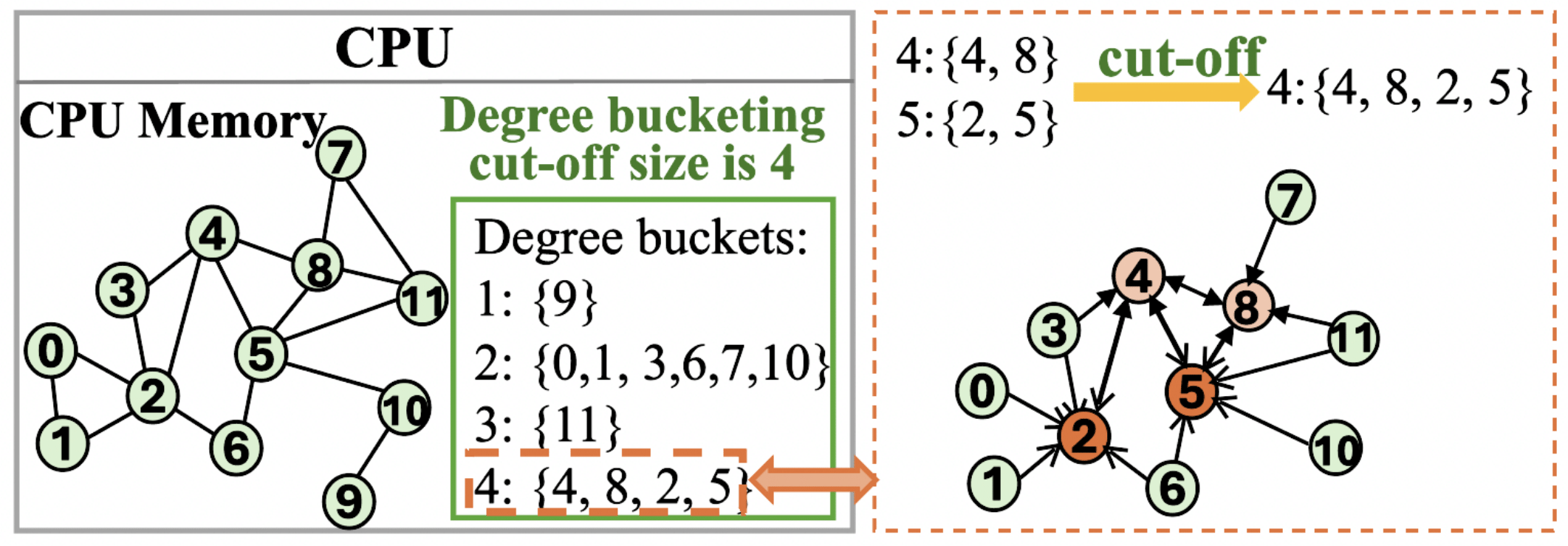 |
Buffalo: Enabling Large-Scale GNN Training via Memory-Efficient Bucketization
HPCA 2025 |
 |
PODC 2024 Adopted by ANL for LLM training with massive sequence lengths, as such GenSLMs and Argonne Earth Systems Model |
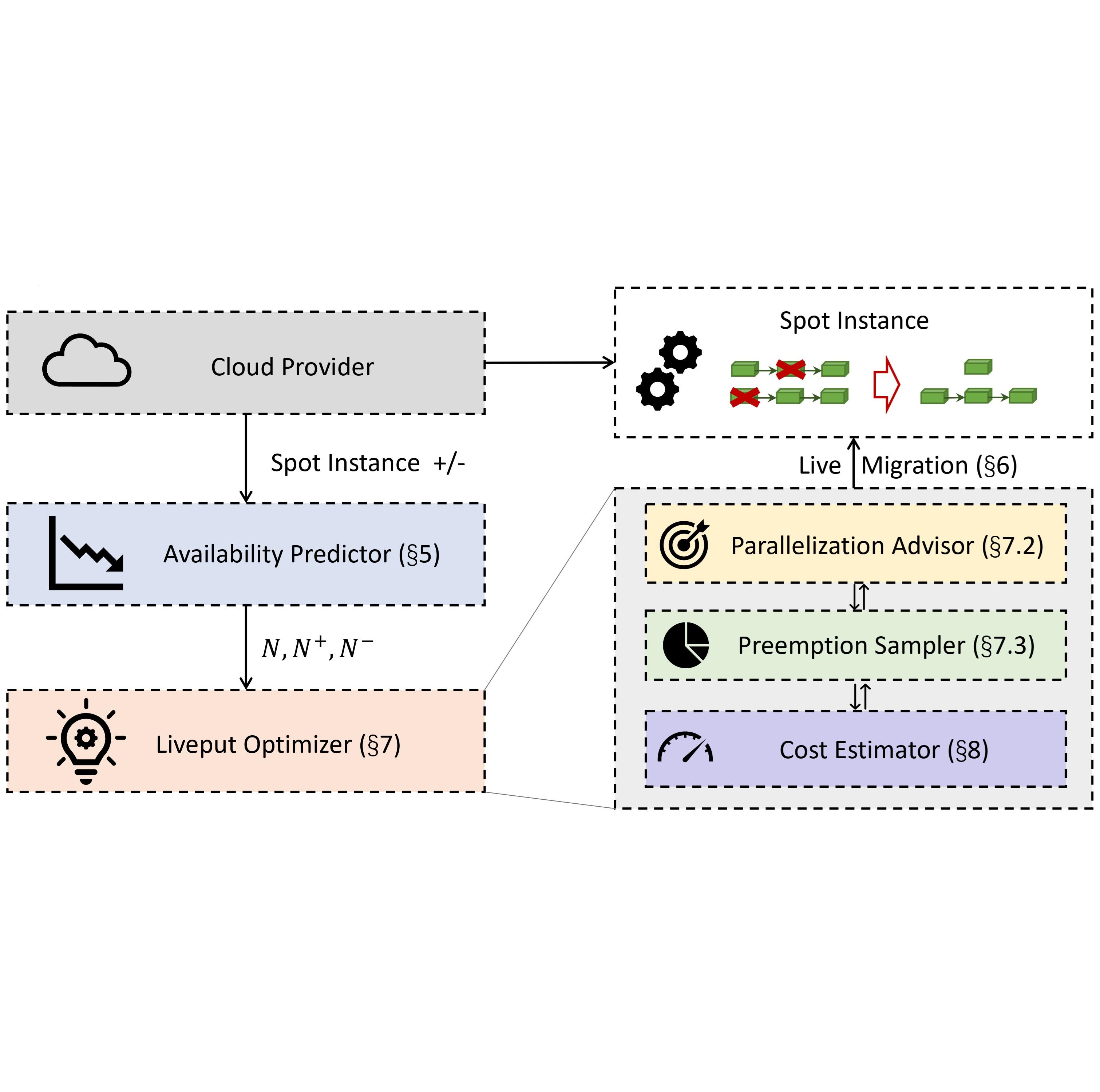 |
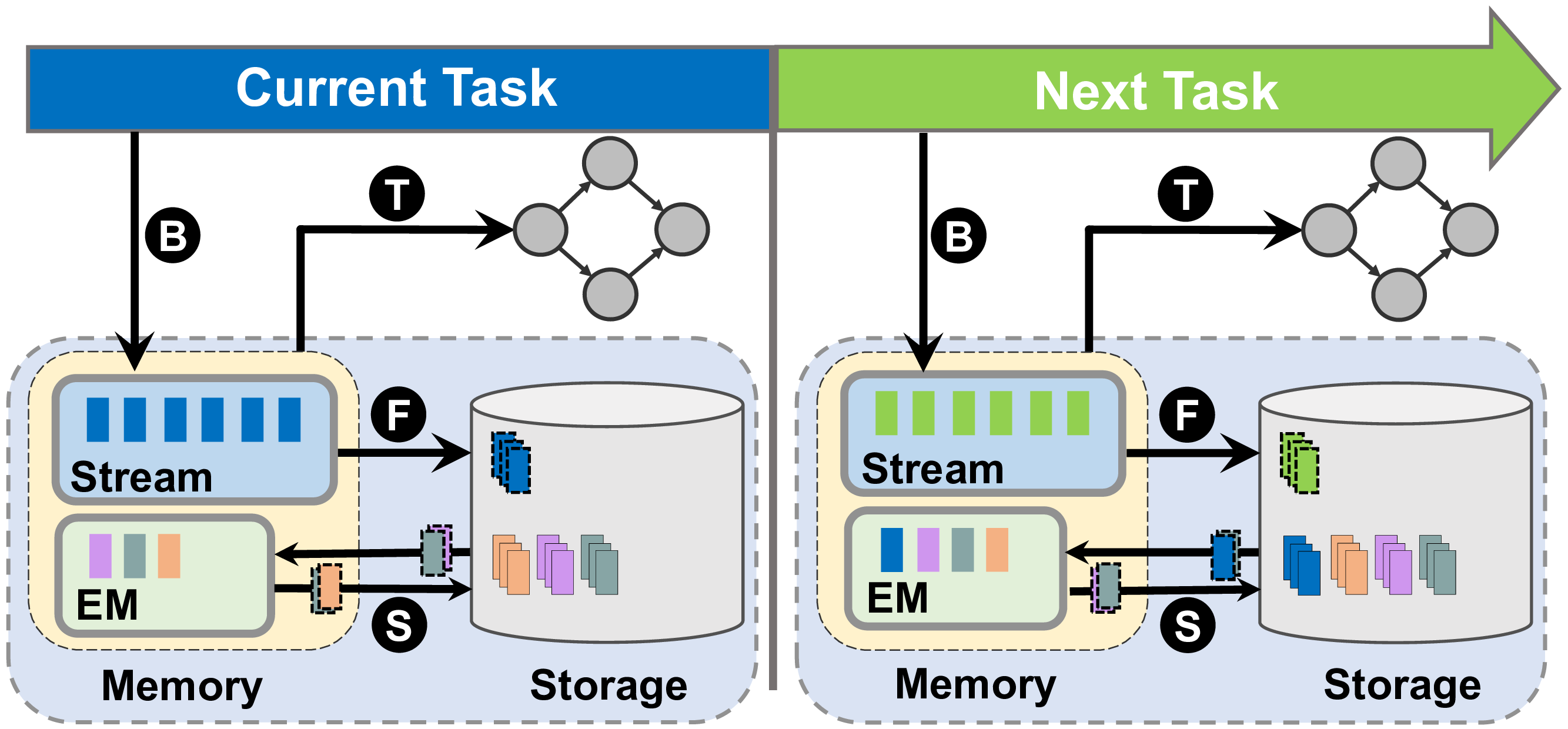
Parcae: Proactive, Liveput-Optimized DNN Training on Preemptible Instances
NSDI 2024 |
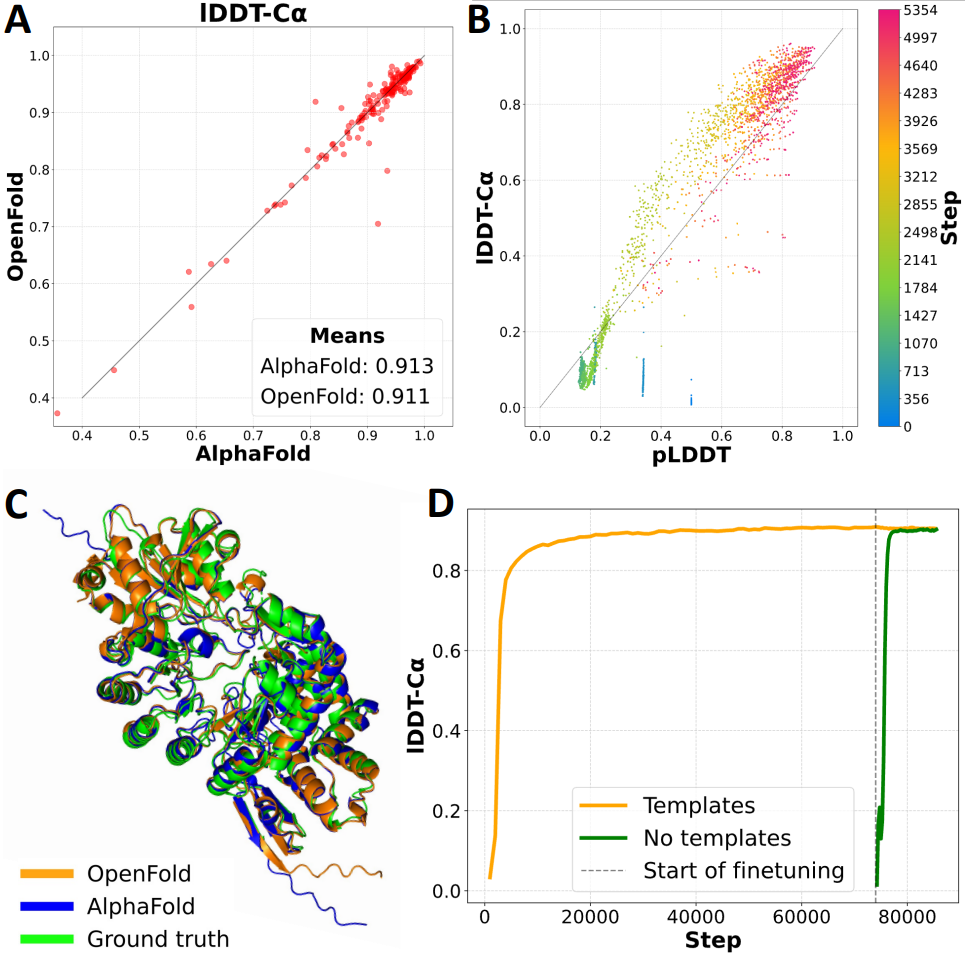 |
Nature Methods 2024 |
 |
AAAI 2024 |
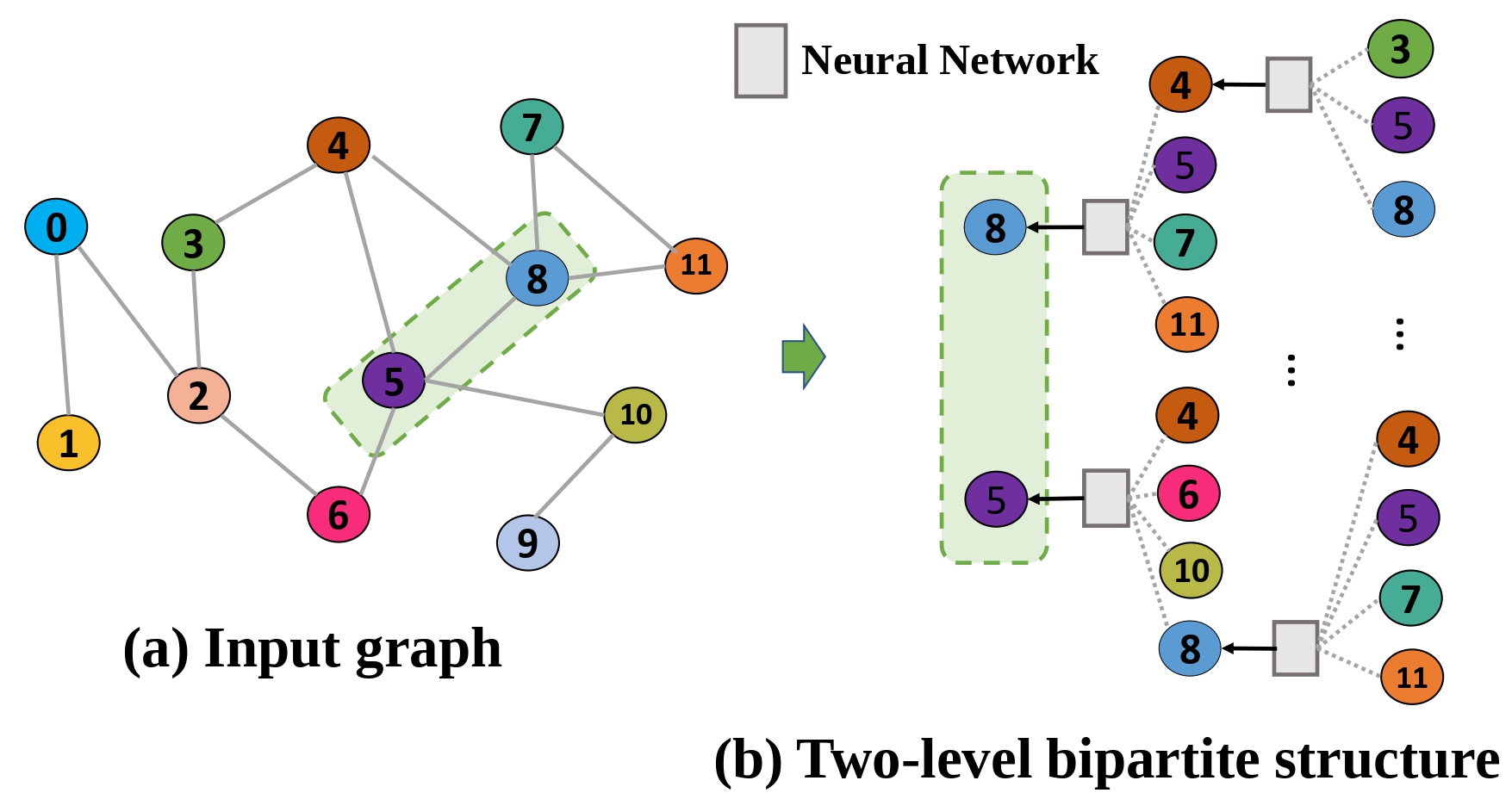 |
Betty: Enabling Large-Scale GNN Training with Batch-Level Graph Partitioning
ASPLOS 2023 |
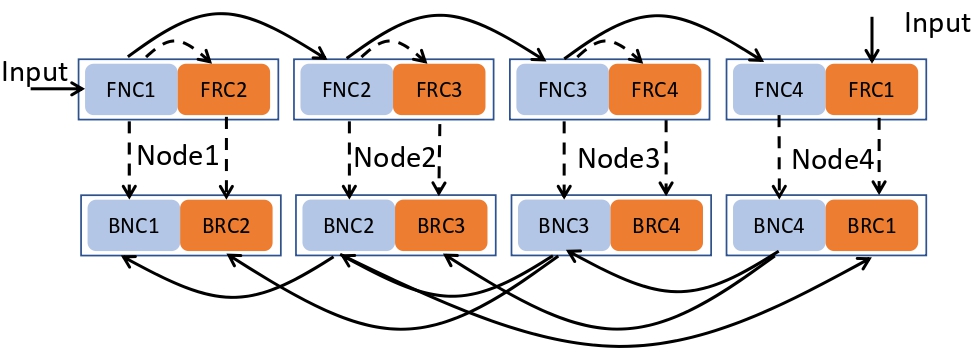 |
Bamboo: Making Preemptible Instances Resilient for Affordable Training of Large DNNs
NSDI 2023 |
 |
Cost-effective On-device Continual Learning over Memory Hierarchy with Miro
MobiCom 2023 |
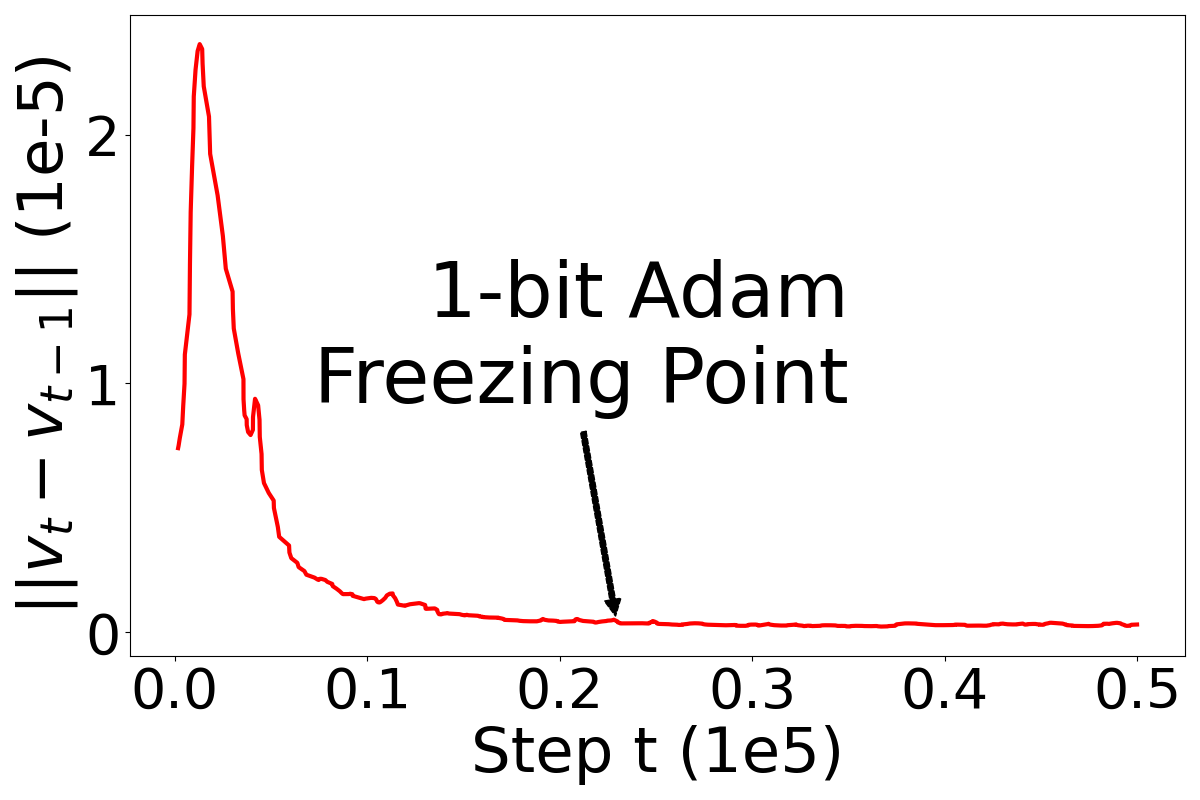 |
Maximizing Communication Efficiency for Large-scale Training via 0/1 Adam
ICLR 2023 |
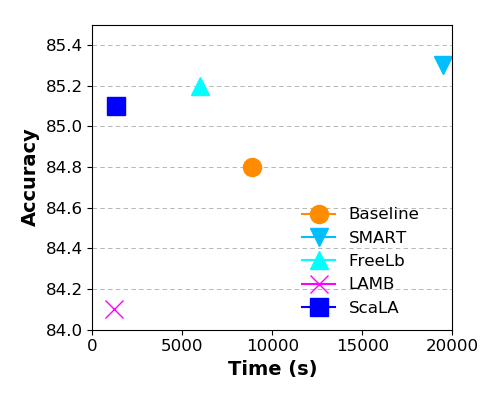 |
ECAI 2023 |
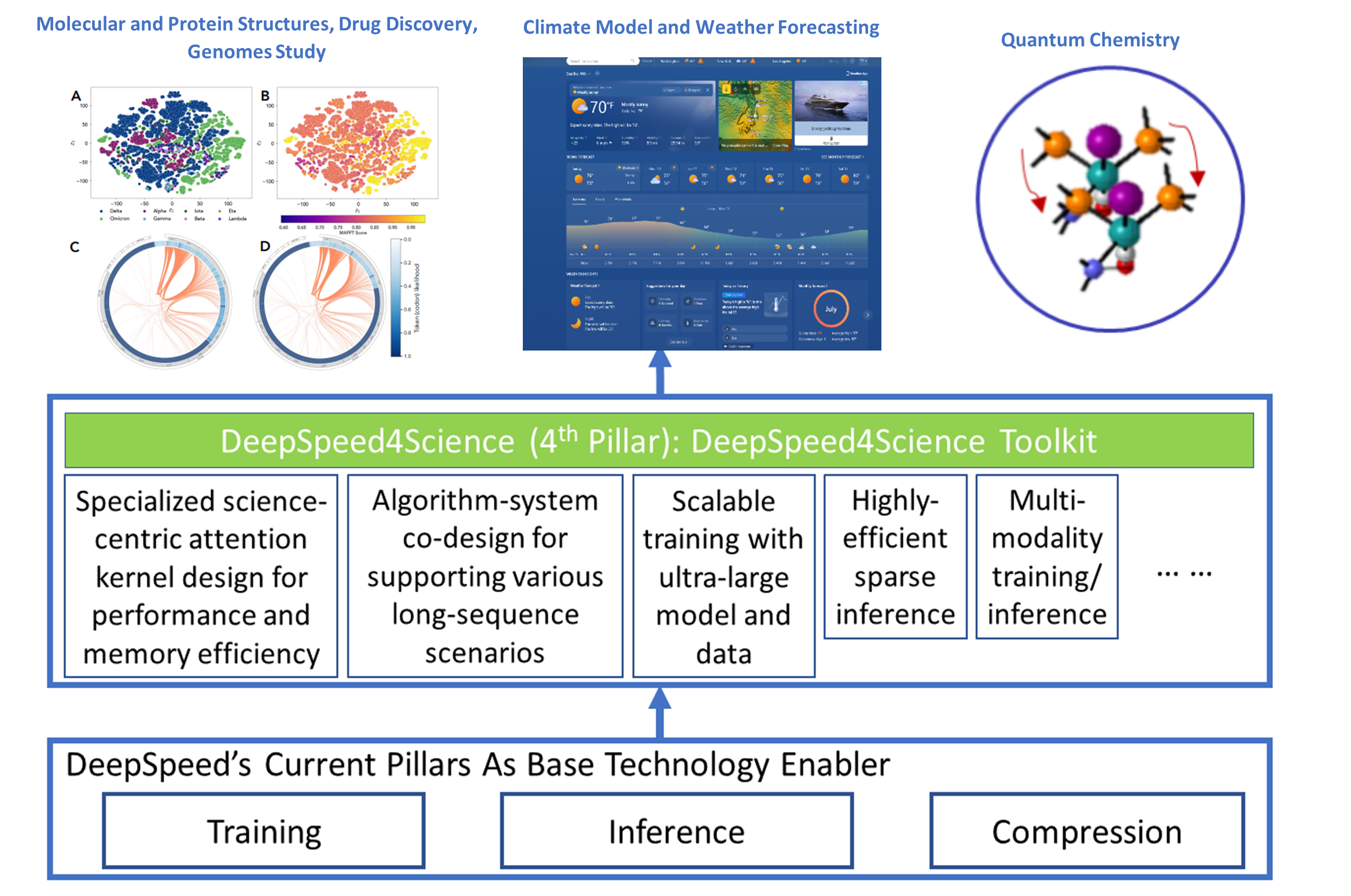 |
NeurIPS AI4Science Workshop 2023 |
 |
Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
ICML 2022 |
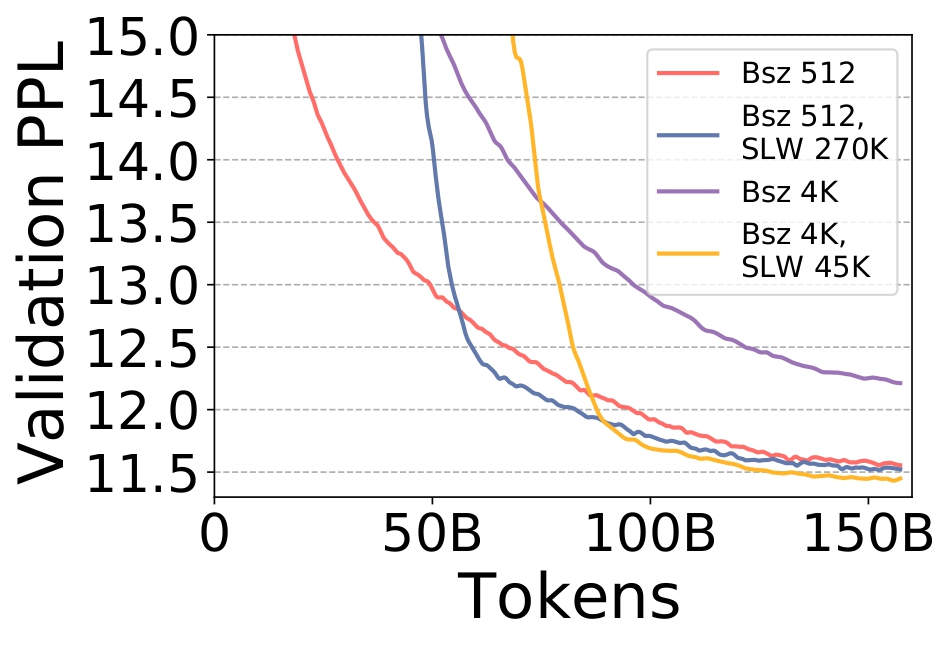 |
The Stability-Efficiency Dilemma: Investigating Sequence Length Warmup for Training GPT Models
NeurIPS 2022 (Spotlight) |
 |
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
ACL 2022 BigScience Workshop The first 176B open-access language model designed and built through the BigScience initiative. |
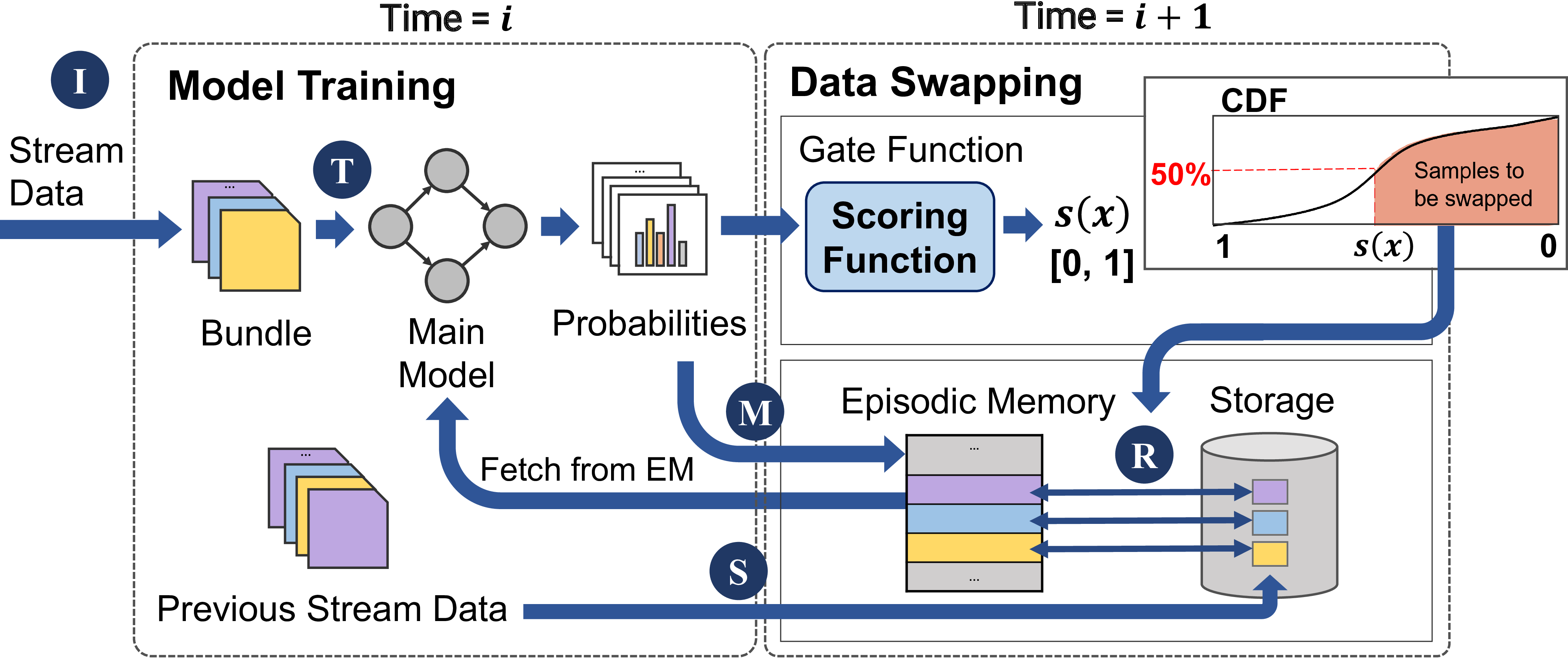 |
CarM: Hierarchical Episodic Memory for Continual Learning
DAC 2022 |
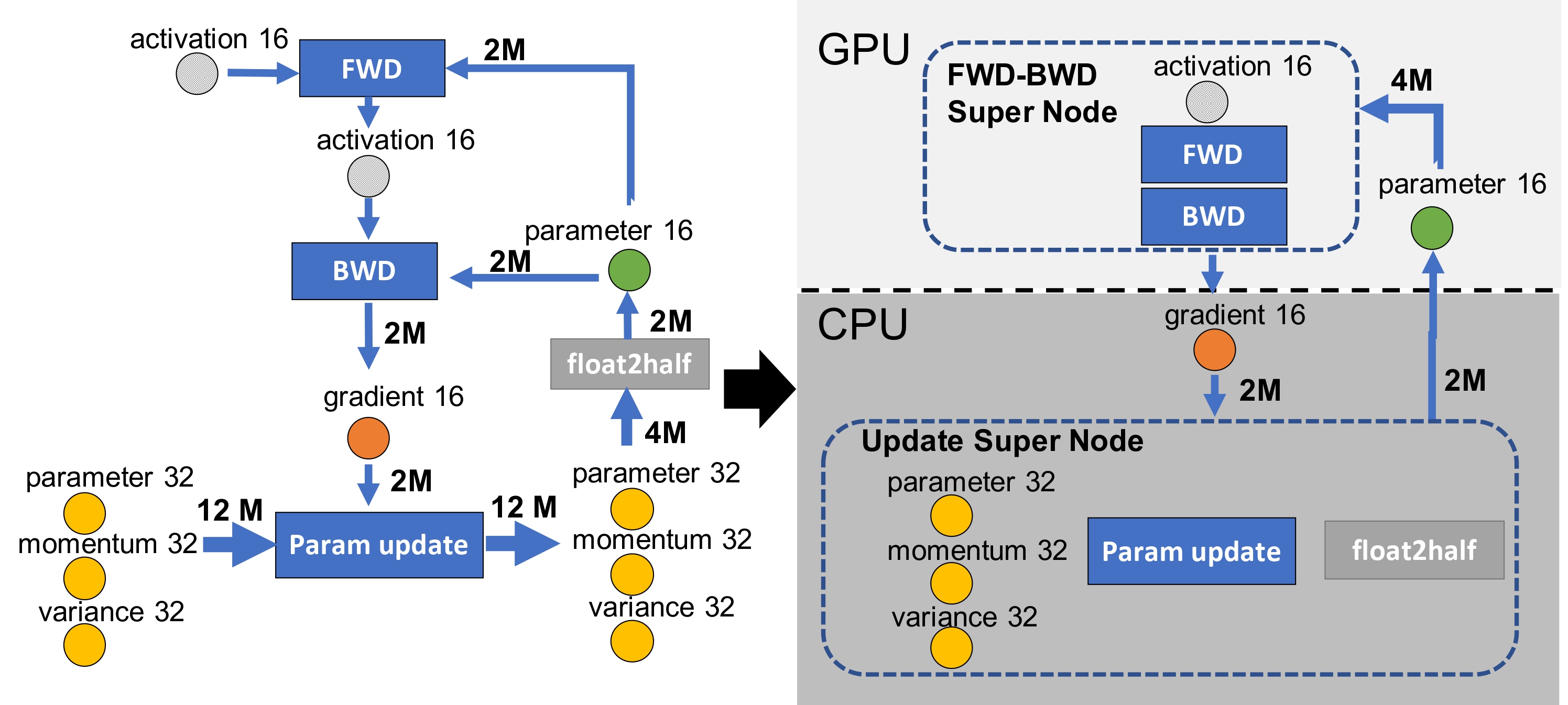 |
ZeRO-Offload: Democratizing Billion-Scale Model Training
USENIX ATC 2021 You can EASILY train 10x bigger models on your GPU with ZeRO-Offload! |
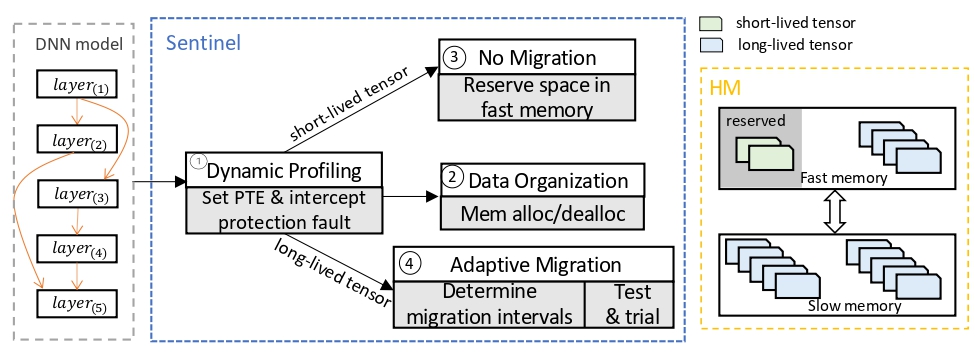 |
Efficient Tensor Migration and Allocation on Heterogeneous Memory Systems for Deep Learning
HPCA 2021 |
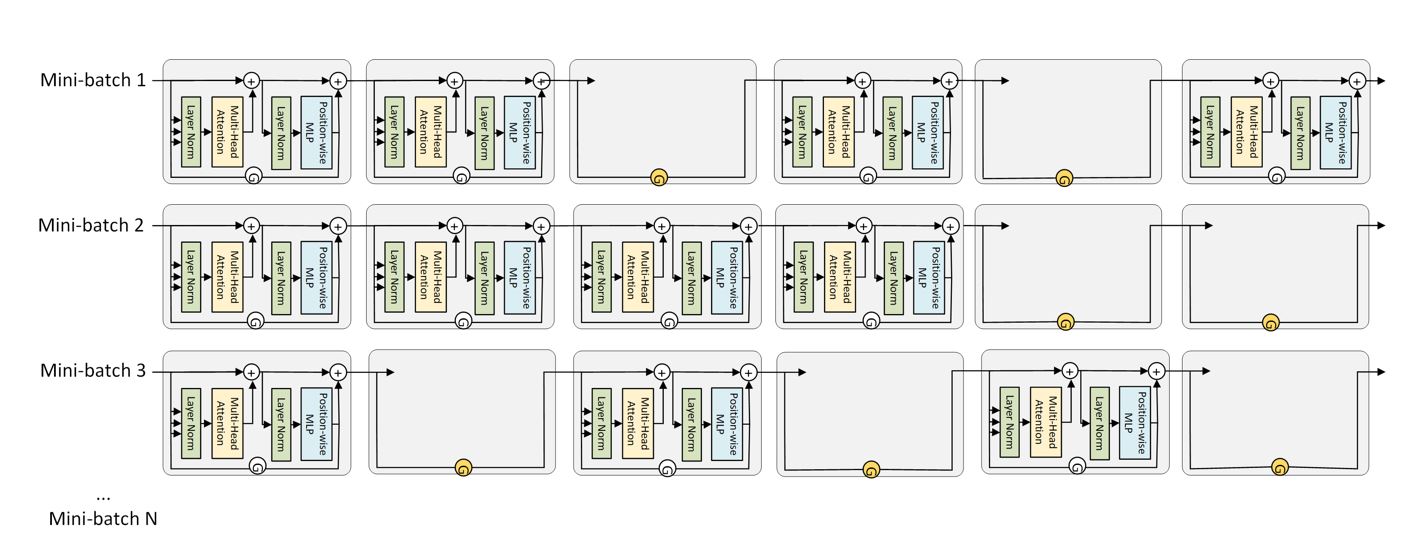 |
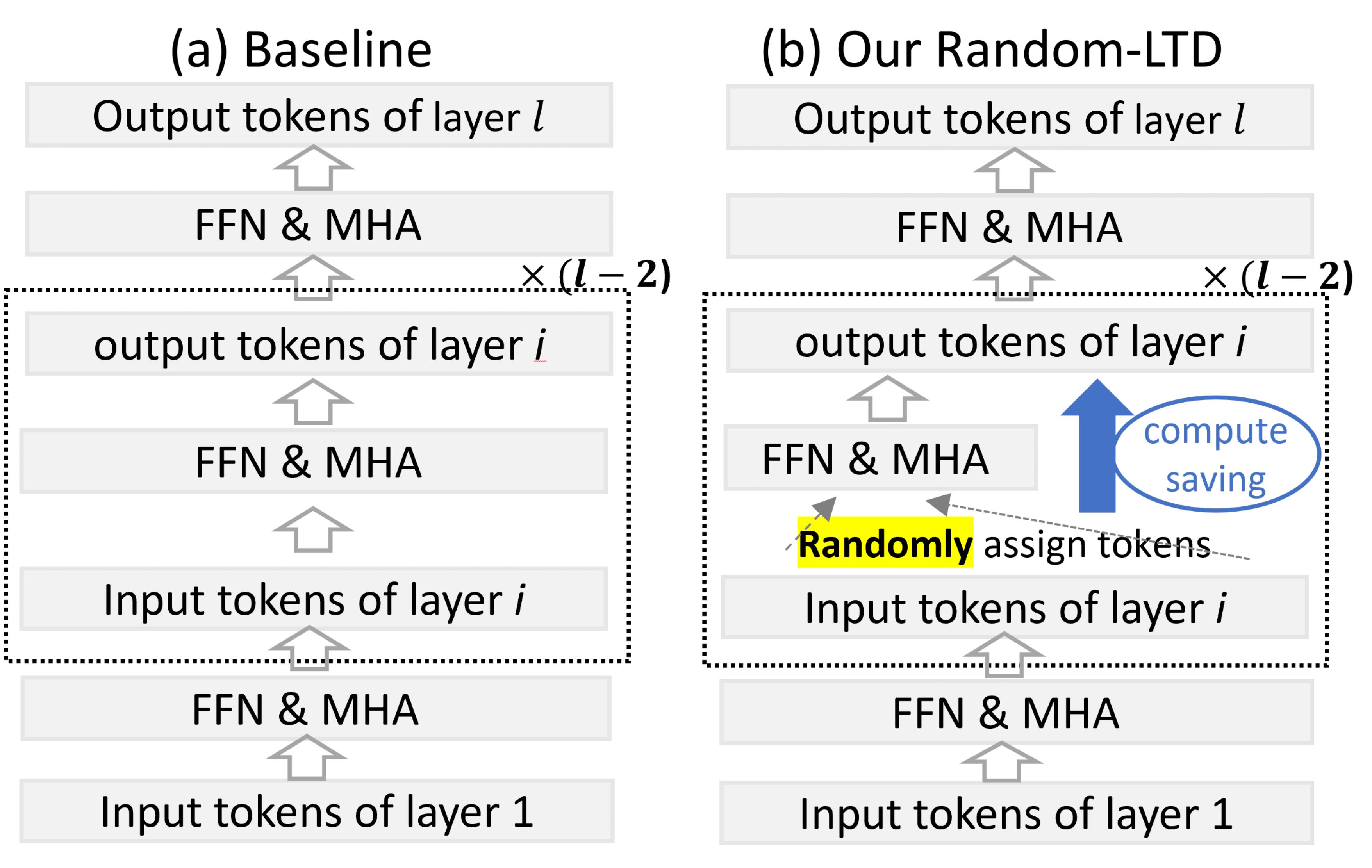
Accelerating Training of Transformer-Based Language Models with Progressive Layer Dropping
NeurIPS 2020 |
Ultra-Fast Inference: We Feel the Need -- The Need for Speed
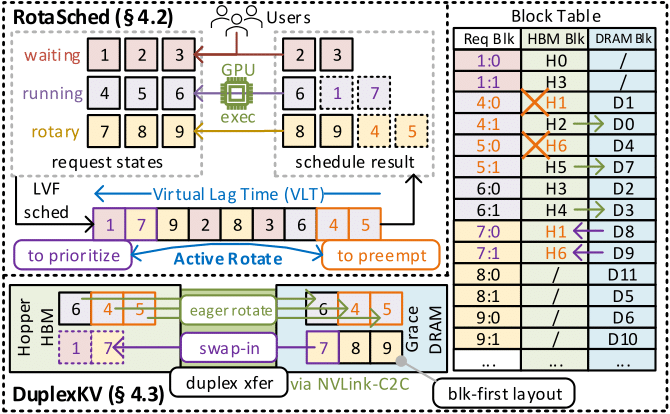 |
SuperInfer: SLO-Aware Rotary Scheduling and Memory Management for LLM Inference on Superchips
MLSys'26 [Project Page] |
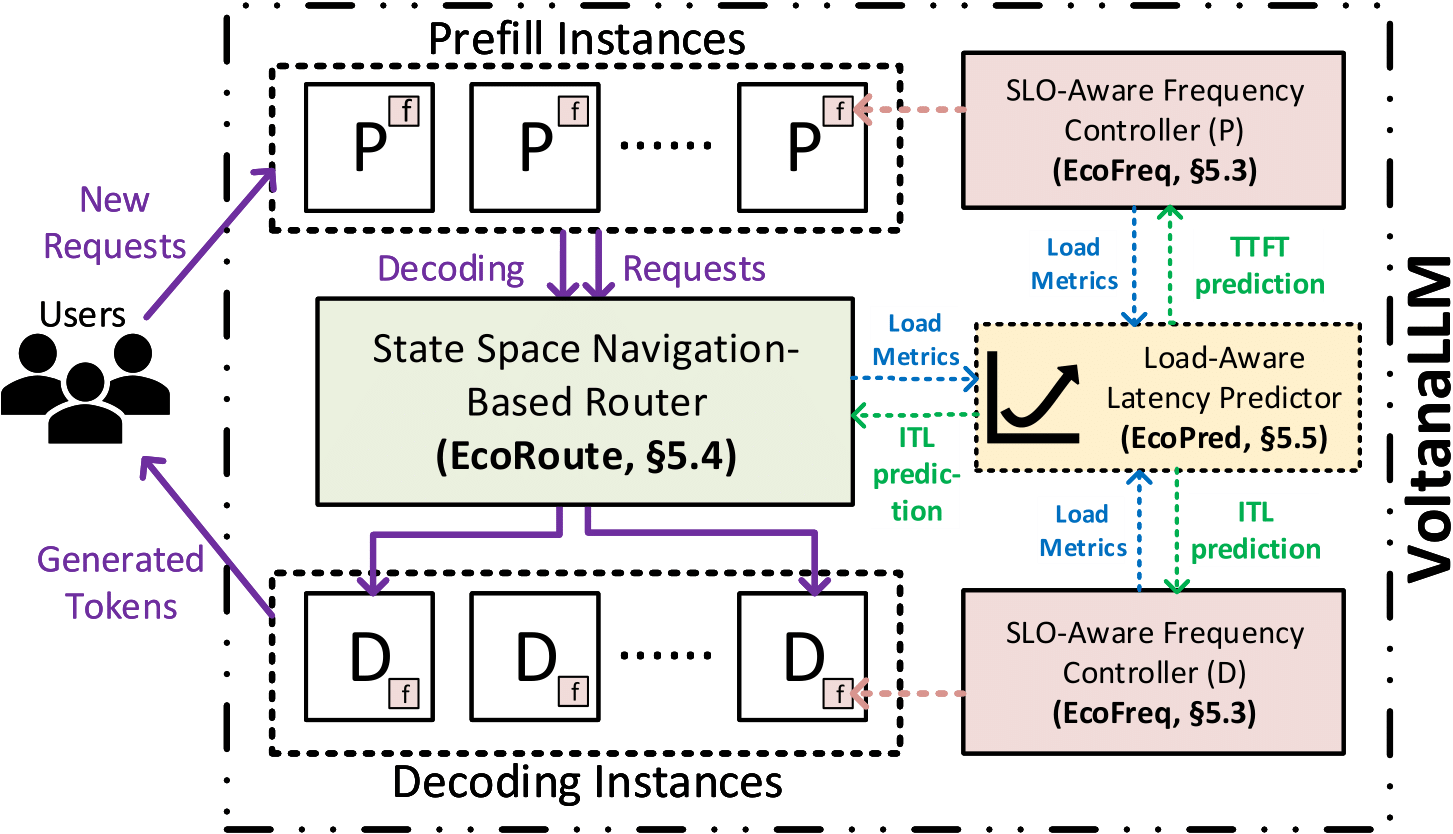 |
ISC'26 [Project Page] |
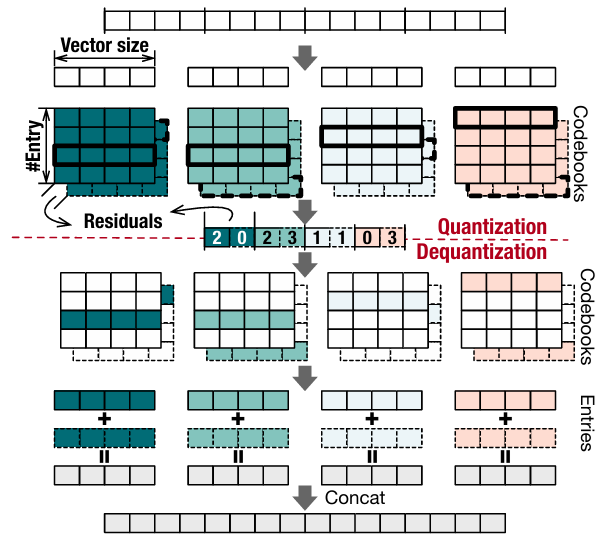 |
VQ-LLM: High-performance Code Generation for Vector Quantization Augmented LLM Inference
HPCA 2025 |
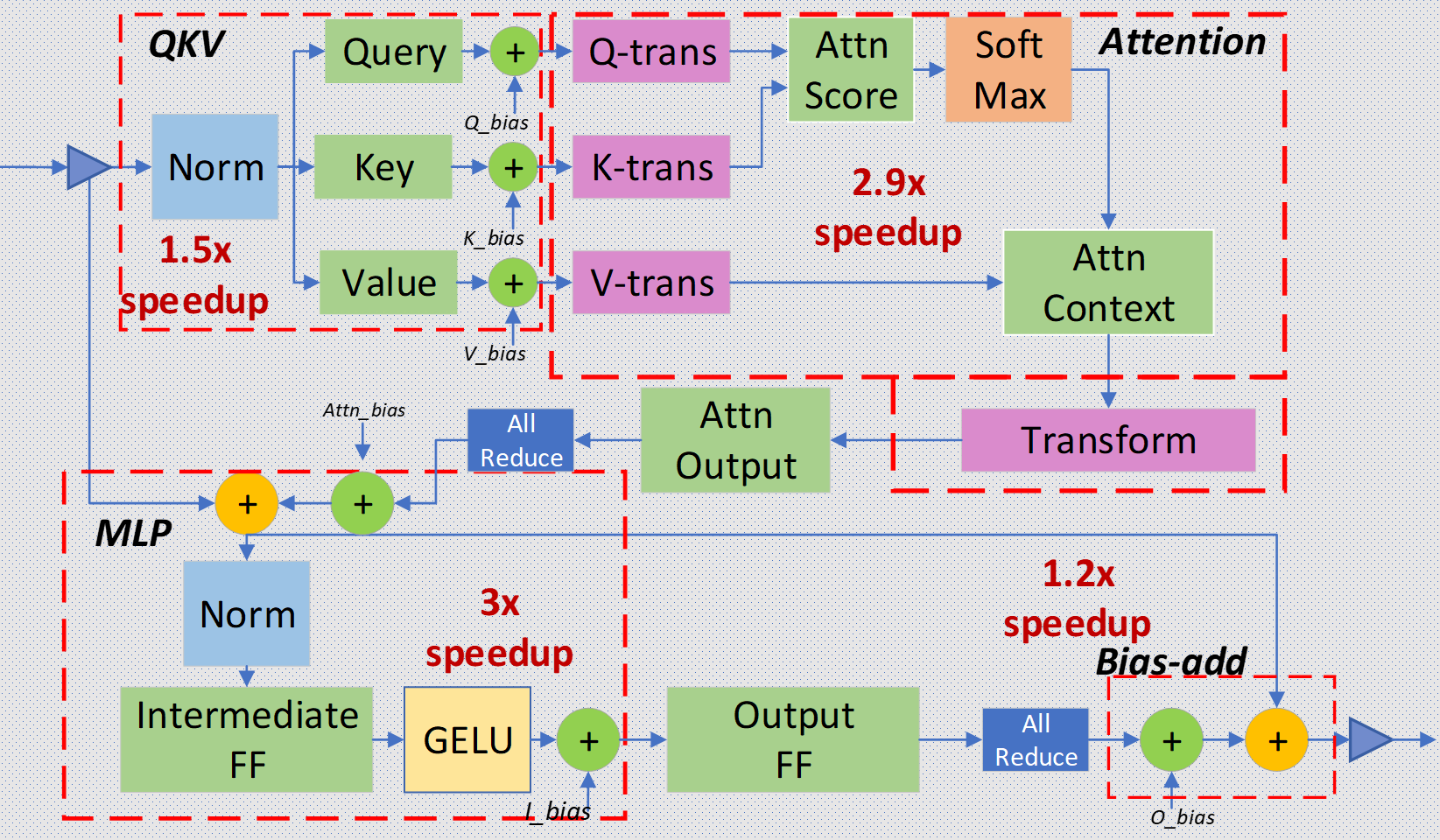 |
DeepSpeed-Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
SC 2022 Comprehensive system optimizations for LLM inference. |
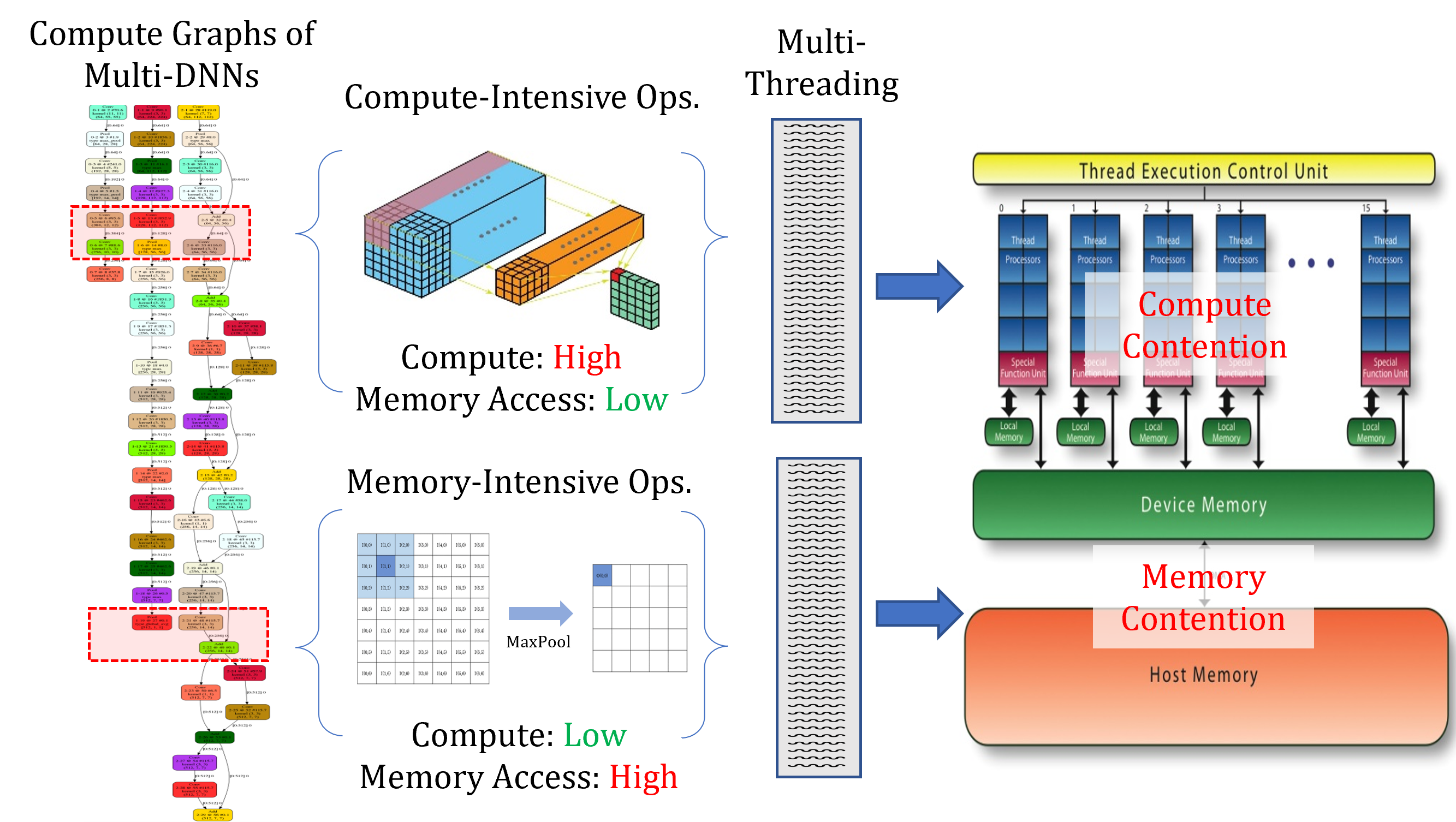 |
A Survey of Multi-Tenant Deep Learning Inference on GPU
MLSys Workshop 2022 |
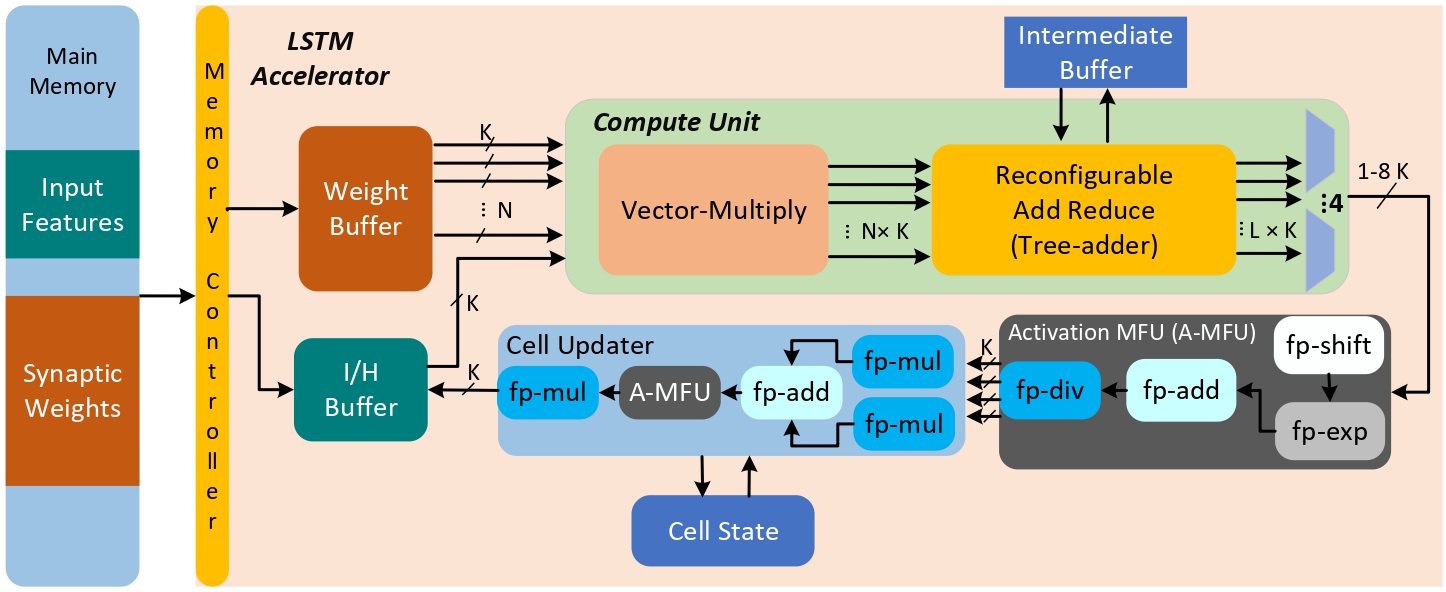 |
SHARP: An Adaptable, Energy-Efficient Accelerator for Recurrent Neural Network
TECS 2022 |
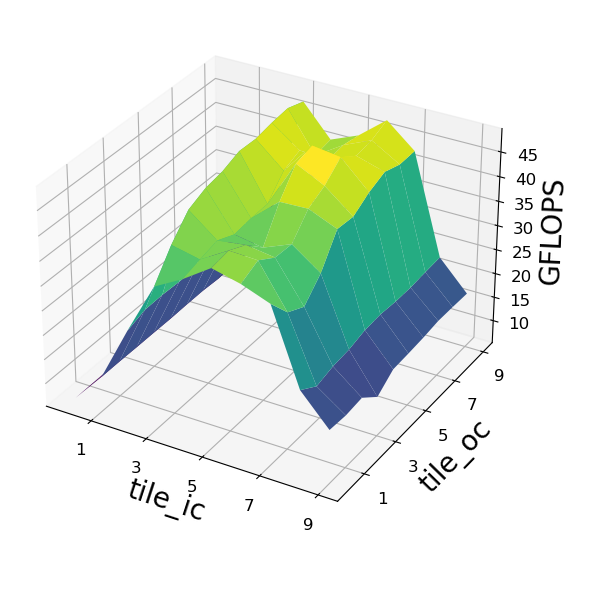 |
DynaTune: Dynamic Tensor Program Optimization in Deep Neural Network Compilation
ICLR 2021 |
 |
DUET: Compiler-Aware Subgraph Scheduling for Tensor Programs on a Coupled CPU-GPU Architecture
IPDPS 2021 |
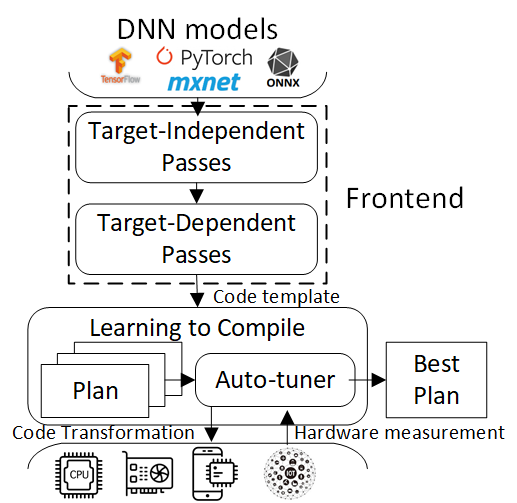 |
AdaTune: Adaptive Tensor Program Compilation Made Efficient
NeurIPS 2020 |
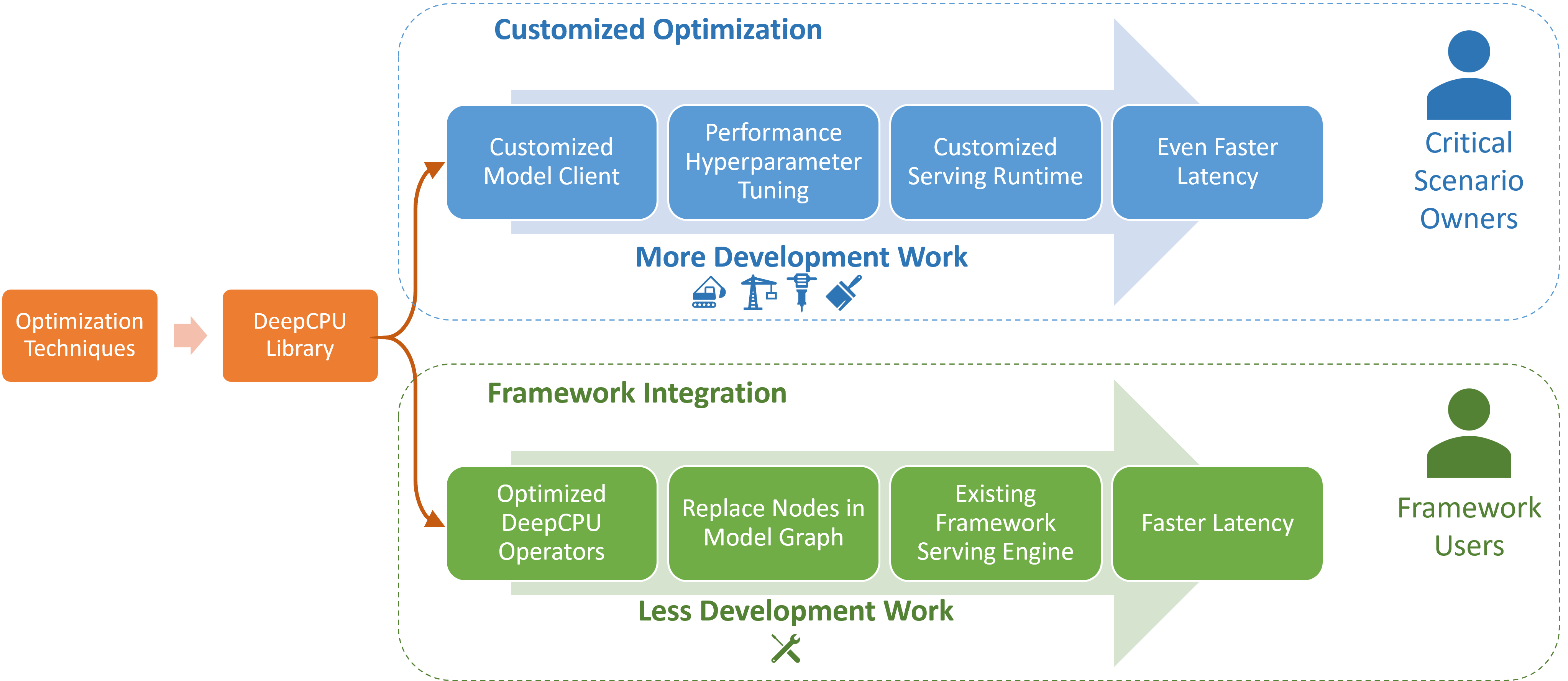 |
Accelerating Large Scale Deep Learning Inference through DeepCPU at Microsoft
USENIX OpML 2019 |
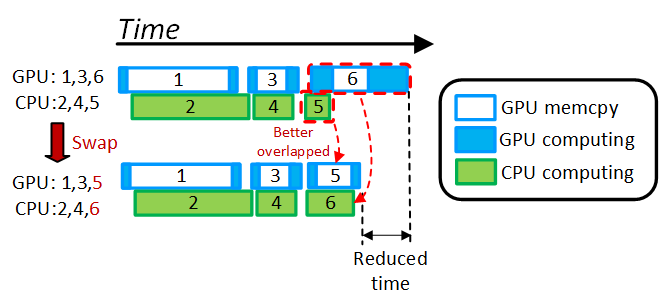
 |
DeepCPU: Serving RNN-based Deep Learning Models 10x Faster
USENIX ATC 2018 Ship DL models in Microsoft with great latency/cost reduction. Selected for Microsoft CTO Kevin Scott's one of the three ``Cool Tech" Showcase 2017. |
Model Compression: The Fast and the Compressed
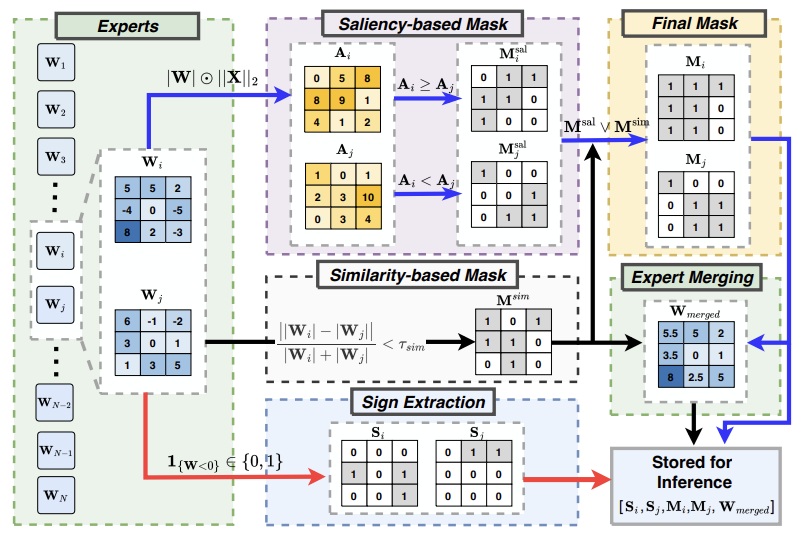 |
ICML 2026 [Project Page] |
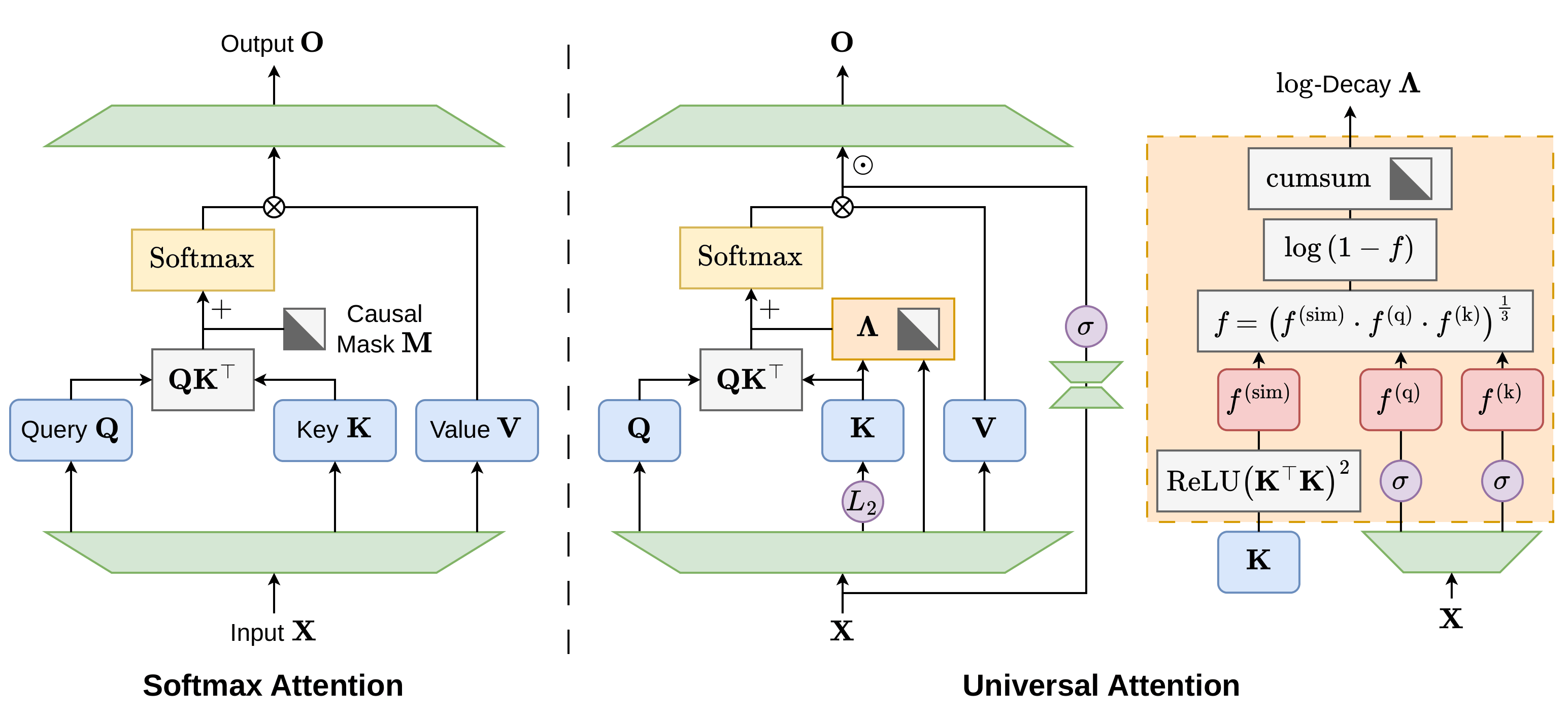 |
A Self-Pruning Transformer: Extreme KV-Cache Compression with Universal Attention
CoLM 2026 |
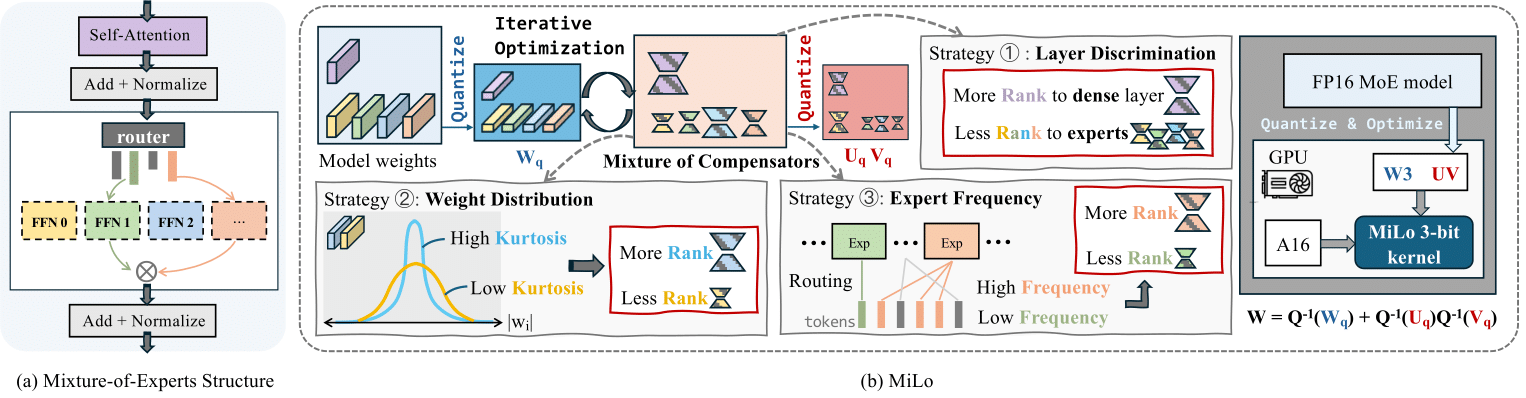 |
MiLo: Efficient Quantized MoE Inference with Mixture of Low-Rank Compensators
MLSys 2025 [Project Page] An end-to-end solution for efficient and accurate 3-bit MoE inference, including DeepSeek-MoE |
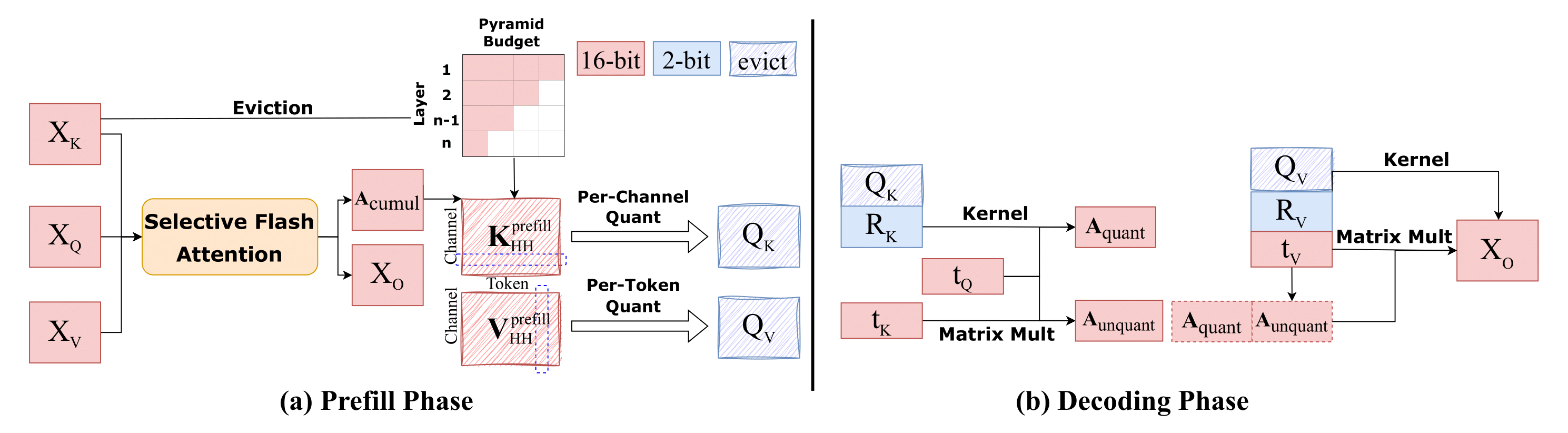 |
ACL Finding 2025 [Project Page] |
 |
FlexGaussian: Flexible and Cost-Effective Training-Free Compression for 3D Gaussian Splatting
ACM MM 2025 (Oral) [Project Page] |
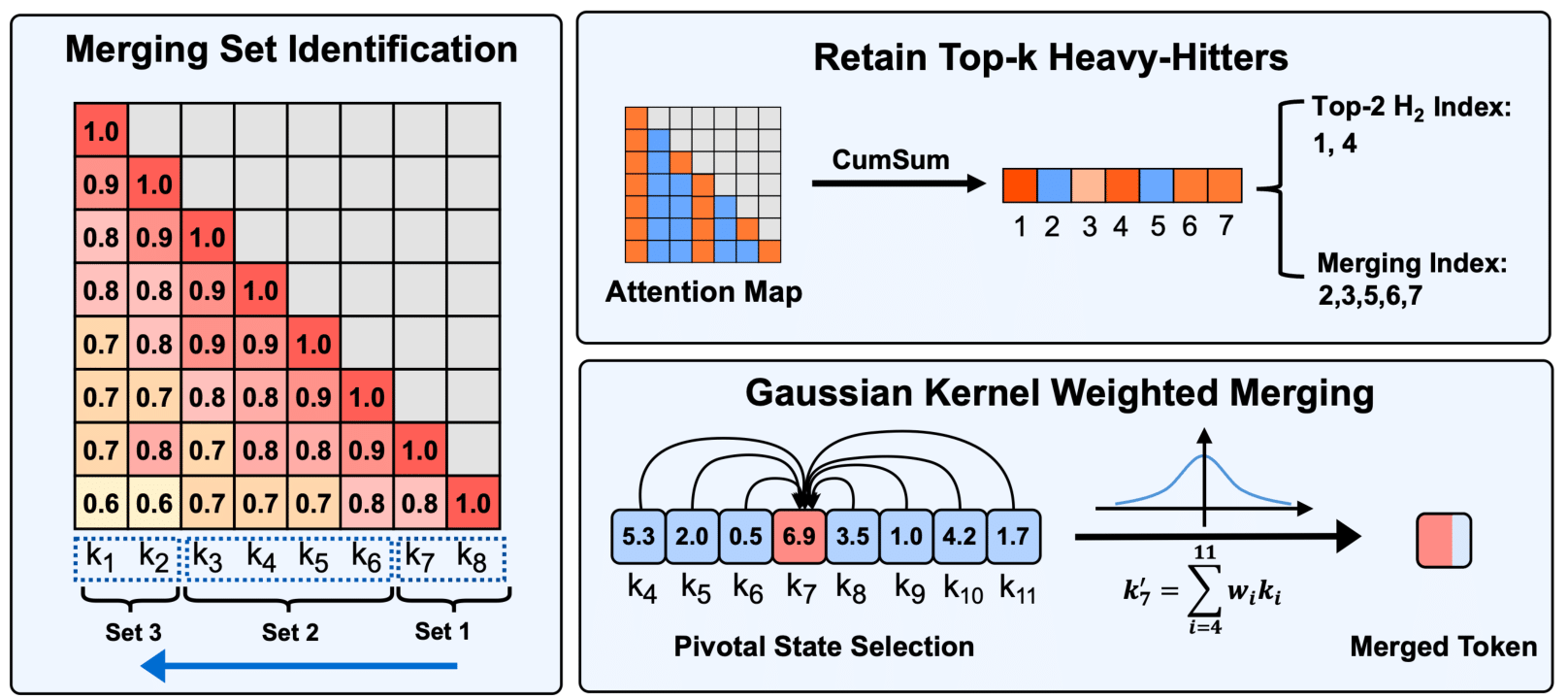 |
Model Tells You Where to Merge: Adaptive KV Cache Merging for LLMs on Long-Context Tasks
Preprint |
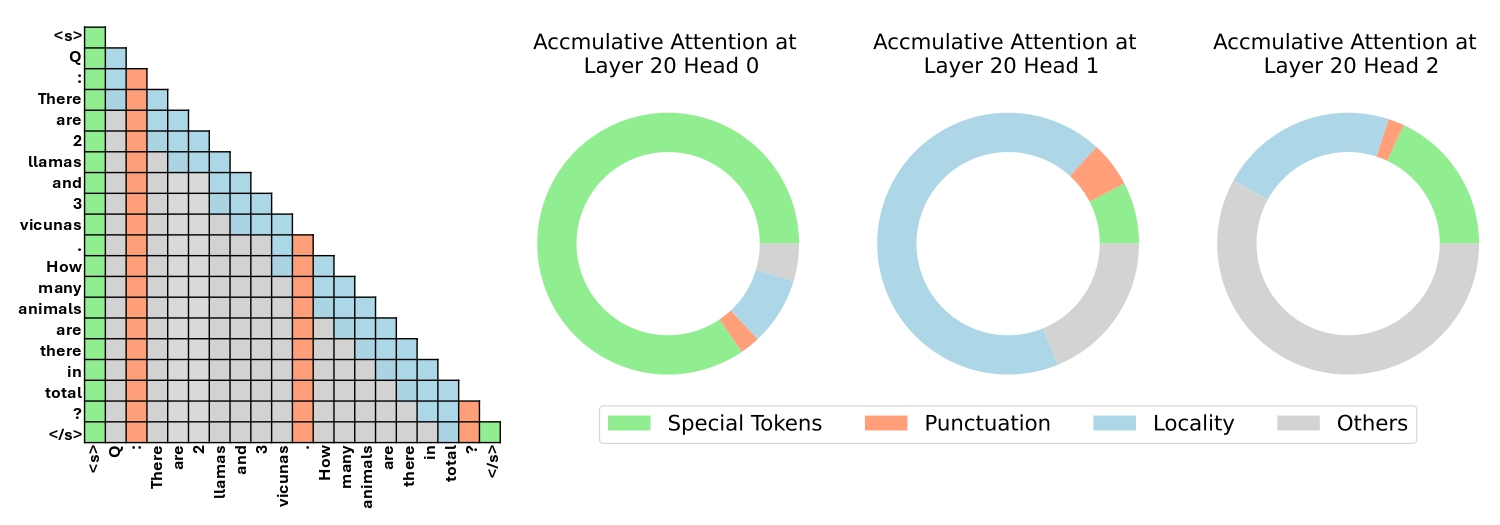 |
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
ICLR 2024 Oral, Honorable Mention of the Outstanding Paper Awards |
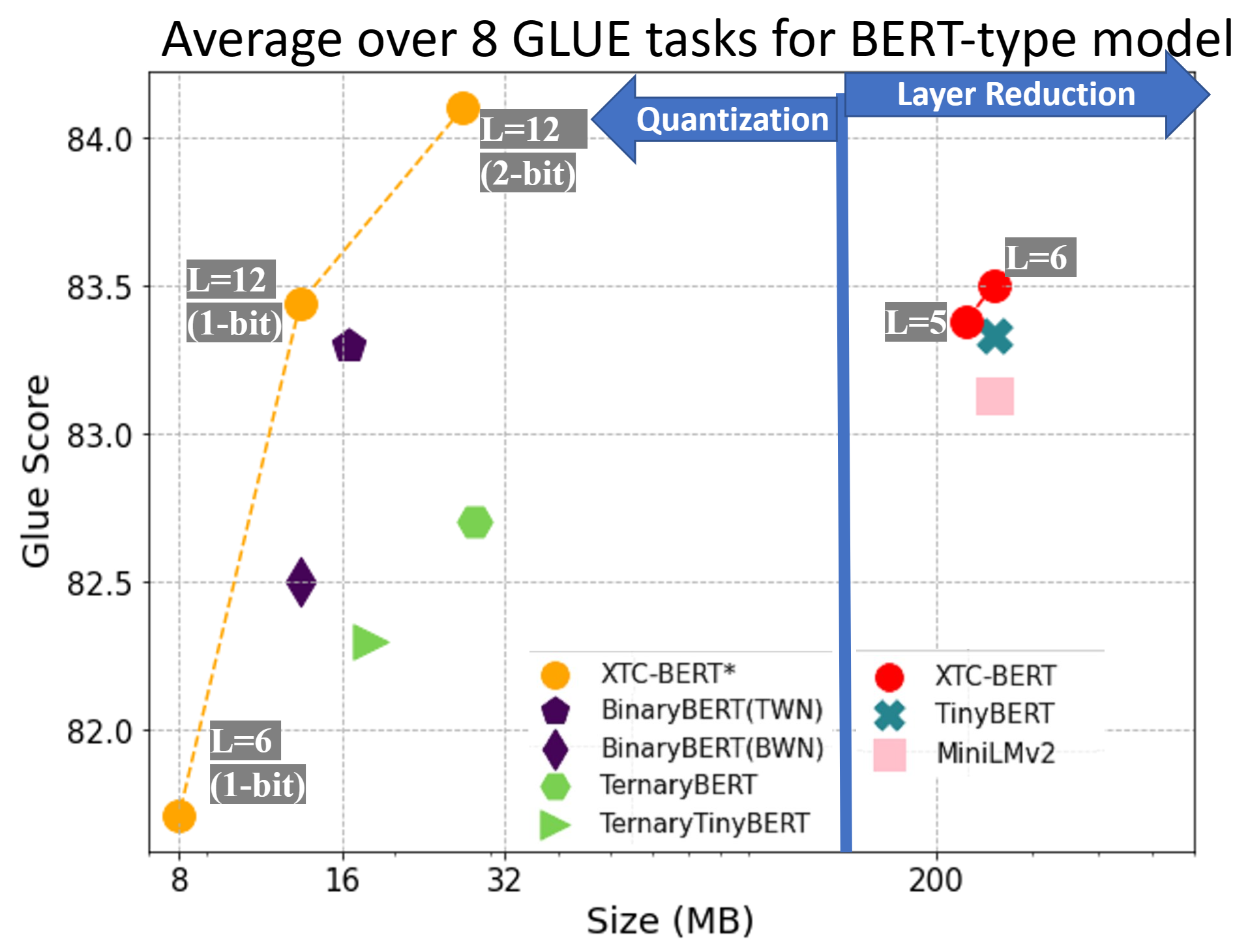 |
Extreme Compression for Pre-trained Transformers Made Simple and Efficient
NeurIPS 2022 (Oral) |
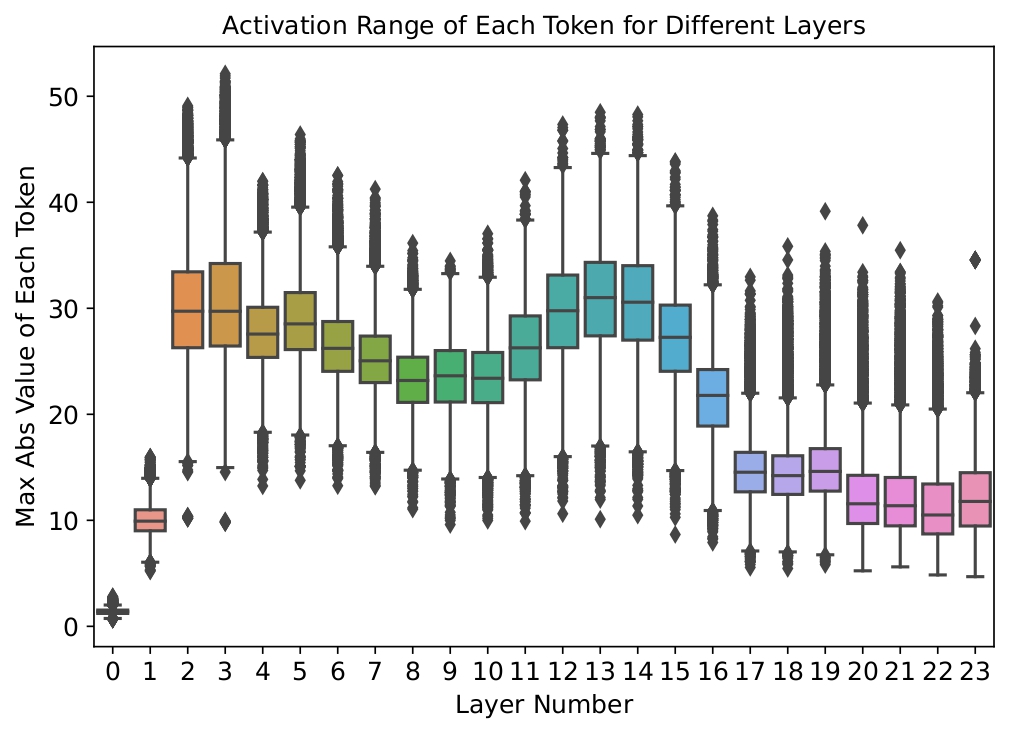 |
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
NeurIPS 2022 (Spotlight) |
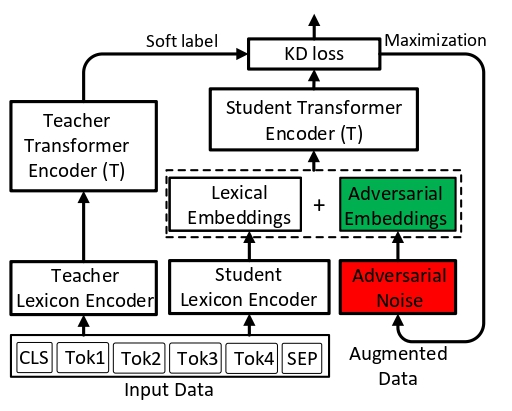 |
Adversarial Data Augmentation for Task-Specific Knowledge Distillation of Pre-Trained Transformers
AAAI 2022 |
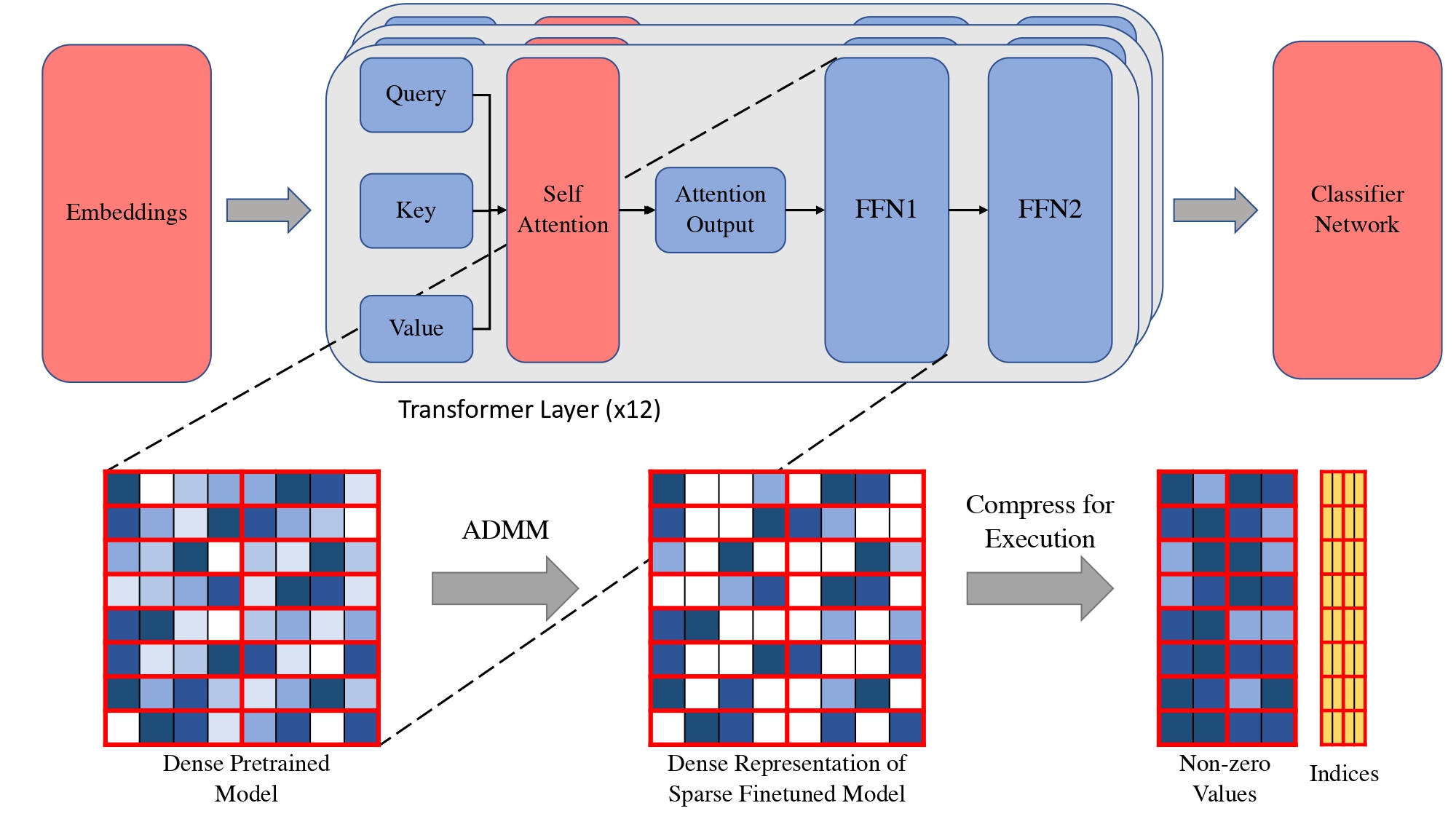 |
NxMTransformer: Semi-Structured Sparsification for Natural Language Understanding via ADMM
NeurIPS 2021 |
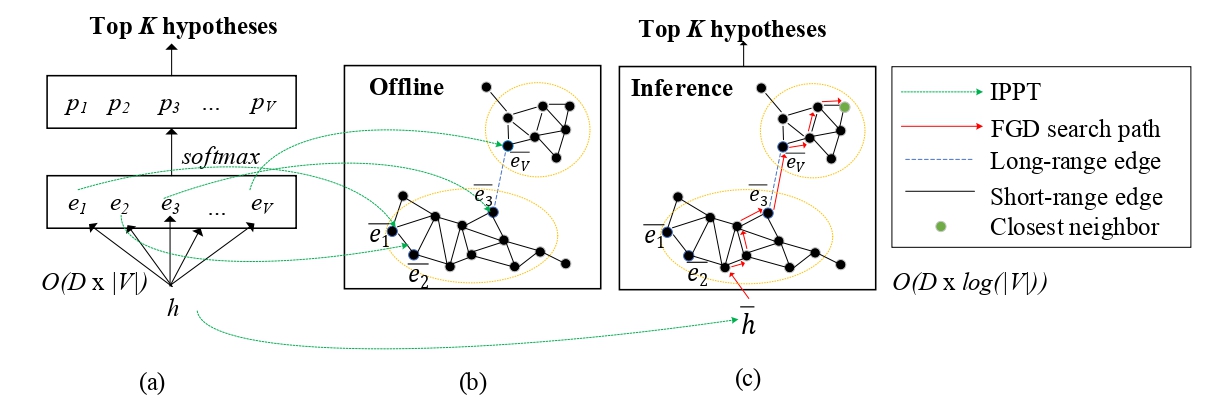 |
Navigating with Graph Representations for Fast and Scalable Decoding of Neural Language Models
NeurIPS 2018 |
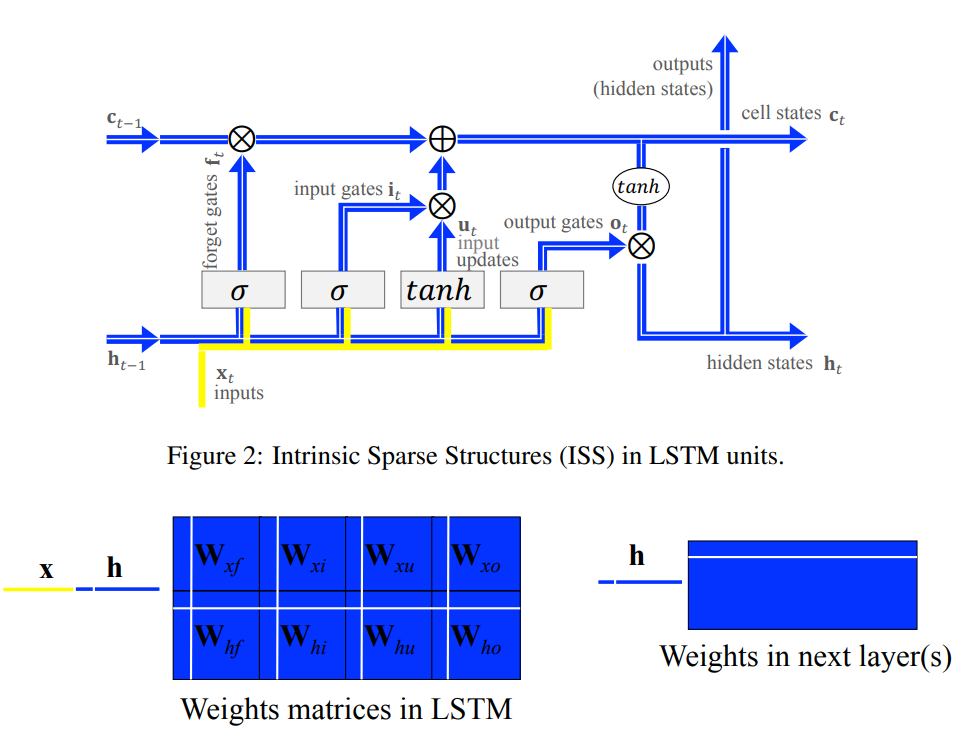 |
Learning Intrinsic Sparse Structures within Long Short-Term Memory
ICLR 2018 |
LLM Reasoning & Agents
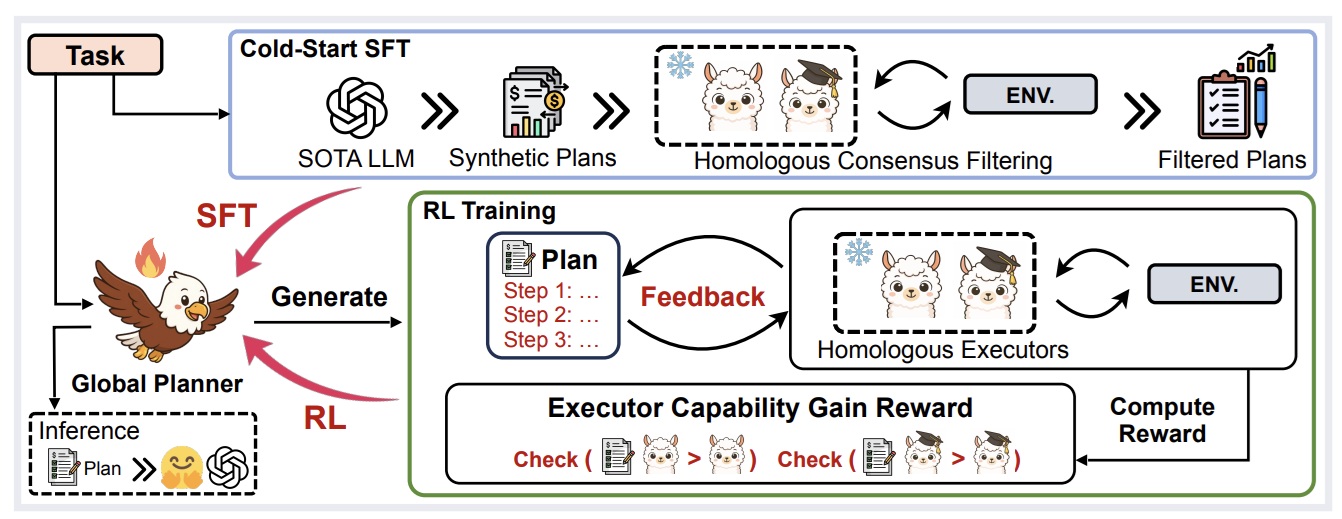 |
ACL 2026 |
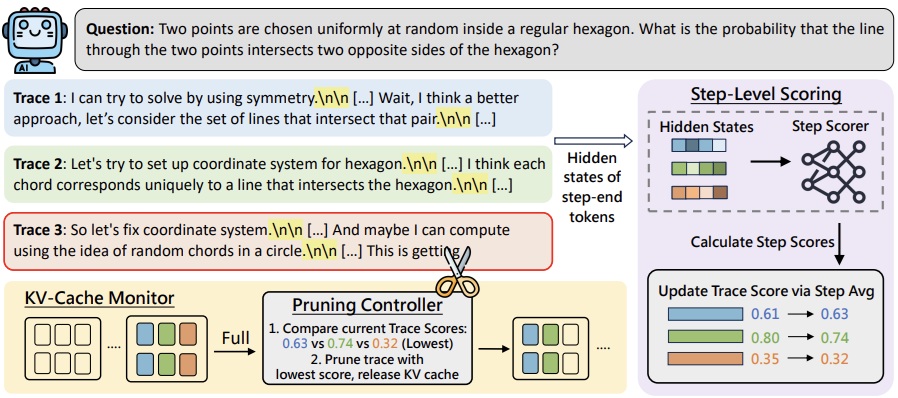 |
ACL Findings 2026 |
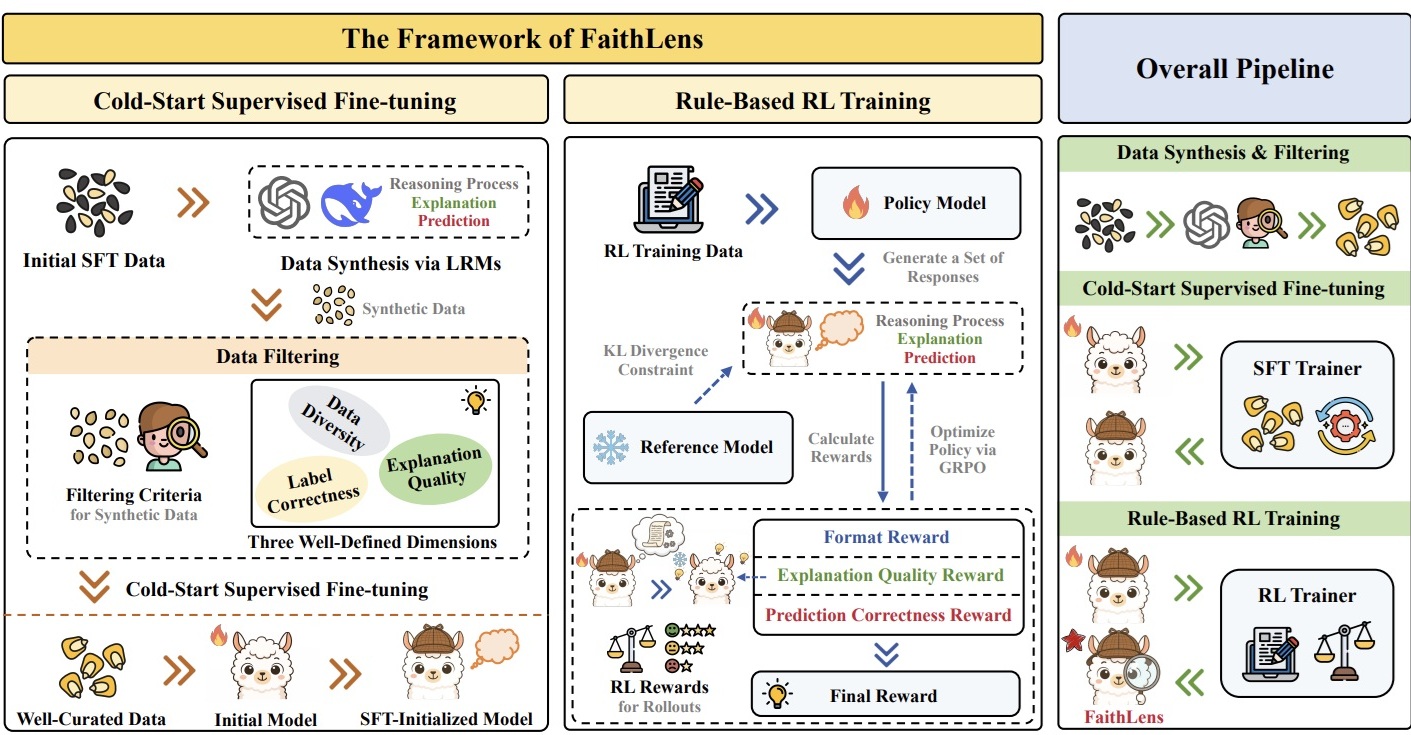 |
FaithLens: Detecting and Explaining Faithfulness Hallucination
ACL Findings 2026 |
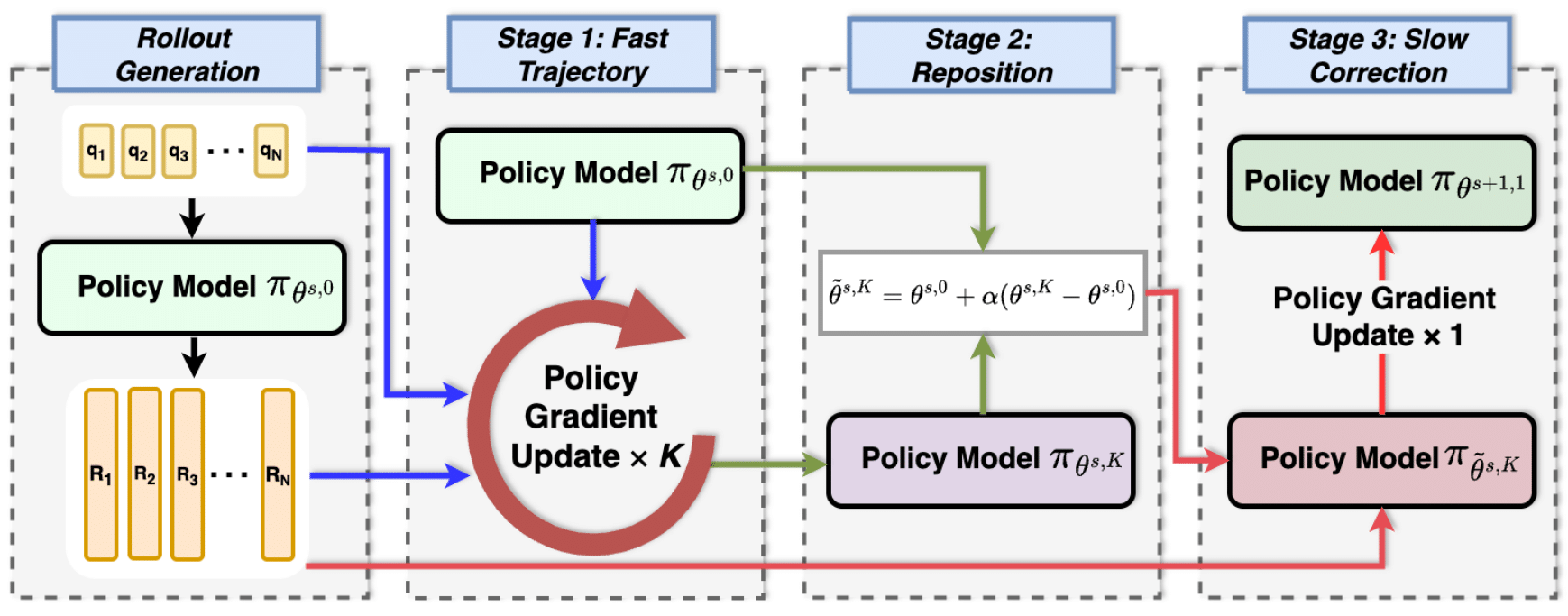 |
Slow-Fast Policy Optimization: Reposition-Before-Update for LLM Reasoning
ICLR 2026 |
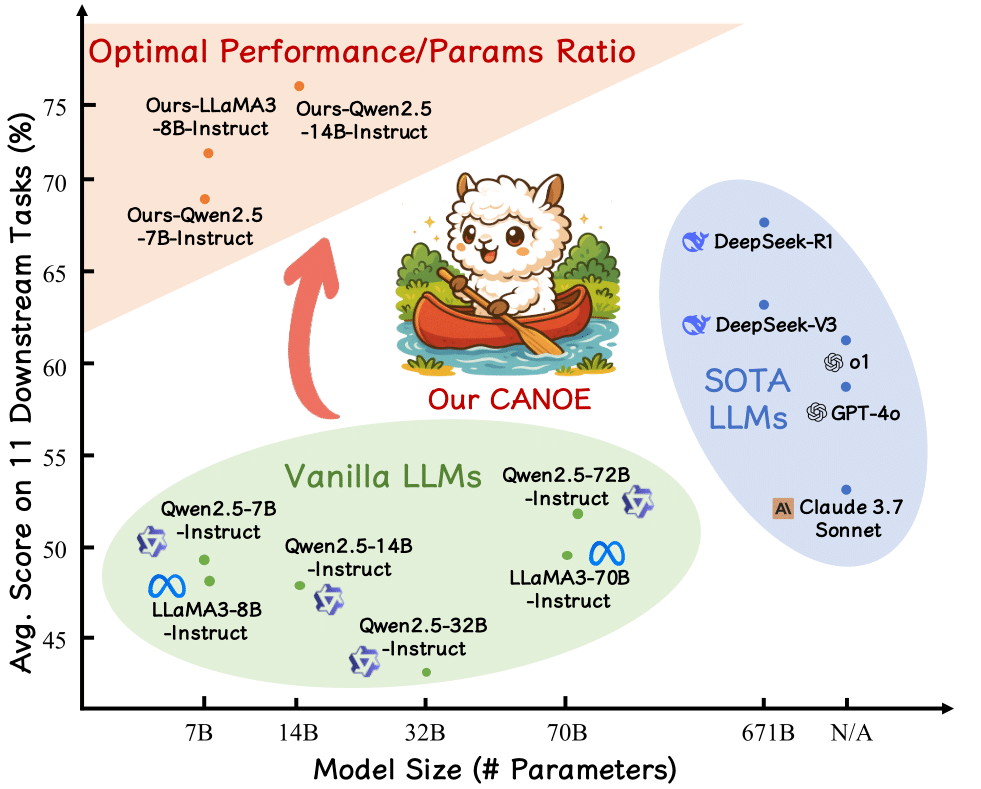 |
AAAI 2026 (Oral) [Project Page] |
 |
MedCite: Can Language Models Generate Verifiable Text for Medicine?
ACL Finding 2025 [Project Page] |
 |
Toward Sensor-In-the-Loop LLM Agent: Benchmarks and Implications
SenSys 2025 |
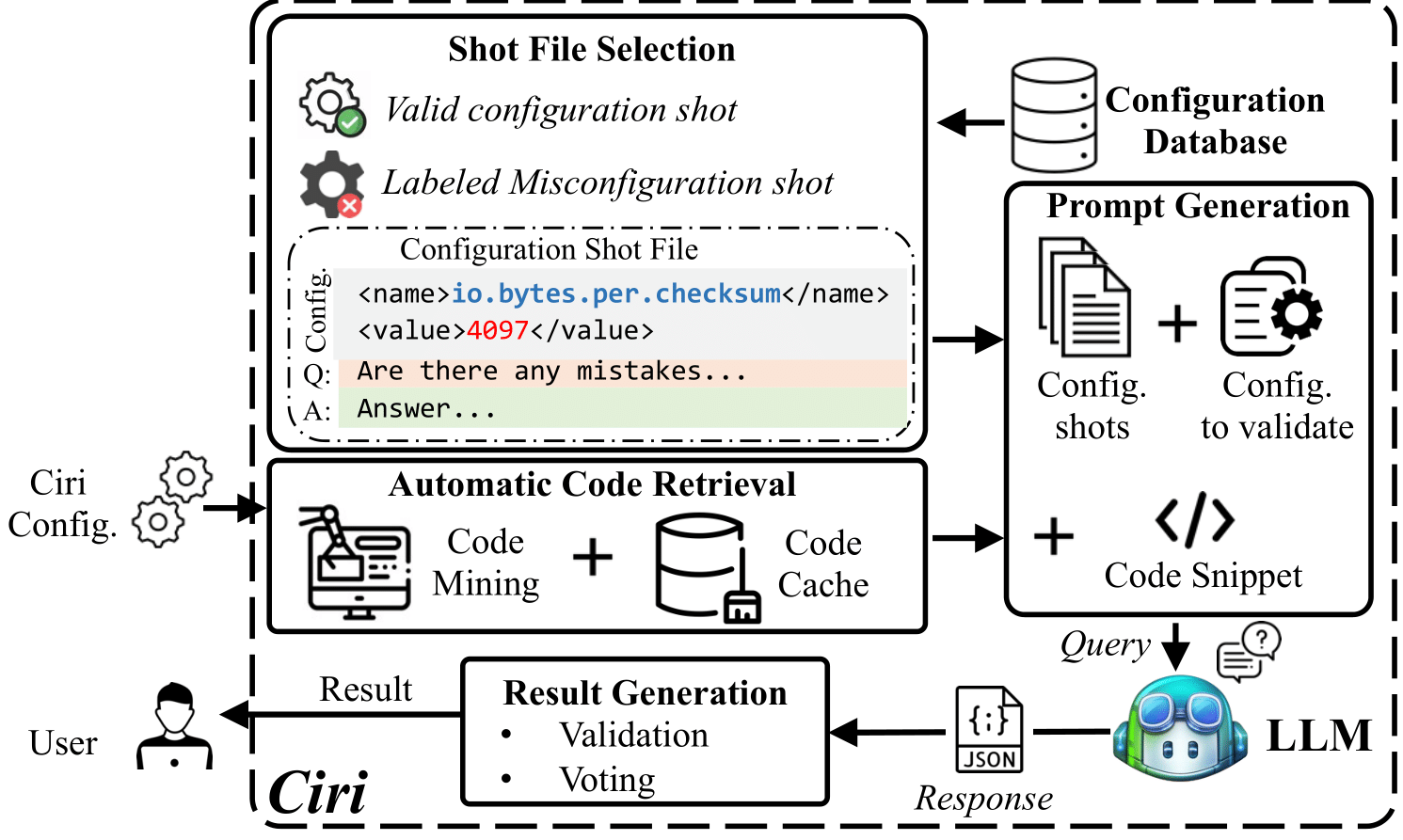 |
Large Language Models as Configuration Validators
ICSE 2025 |
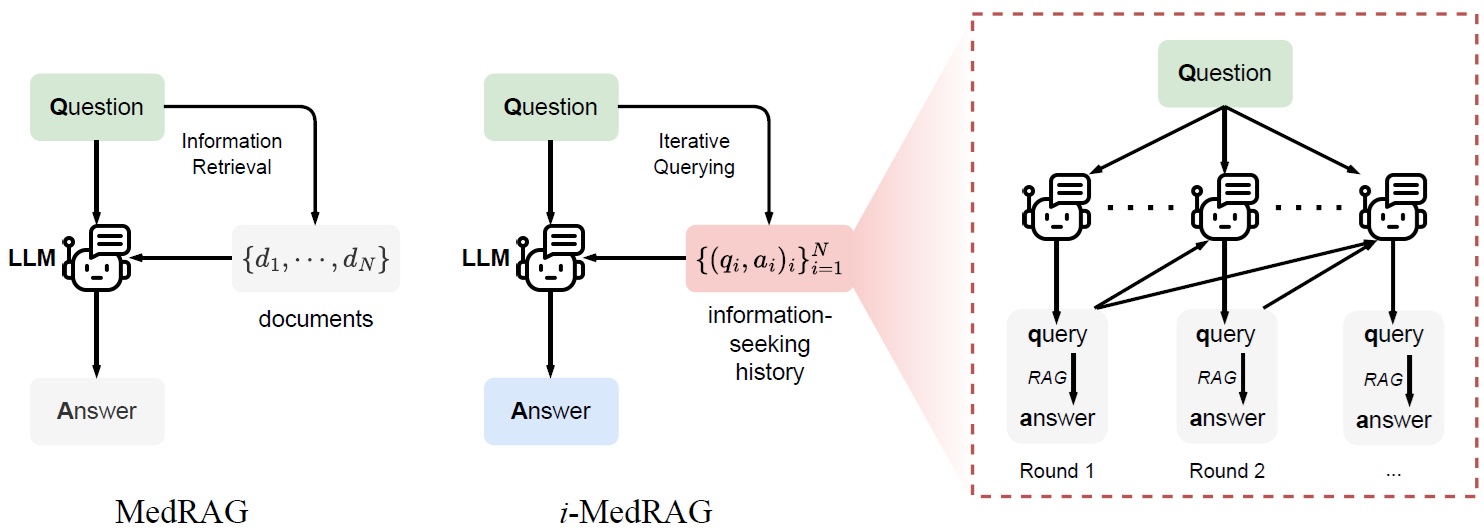 |
Improving Retrieval-Augmented Generation in Medicine with Iterative Follow-up Questions
Pacific Symposium on Biocomputing 2024 |
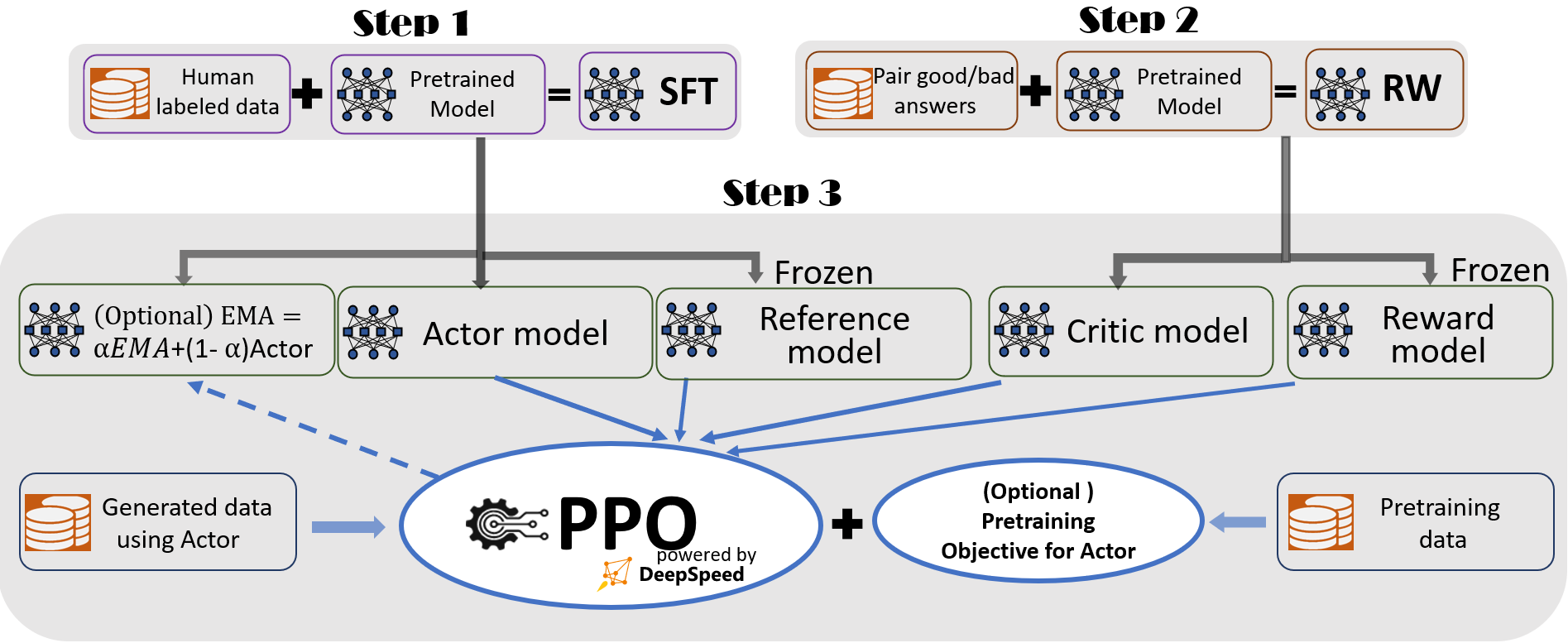 |
DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
Preprint |
Multimodal & Vision-Language Models
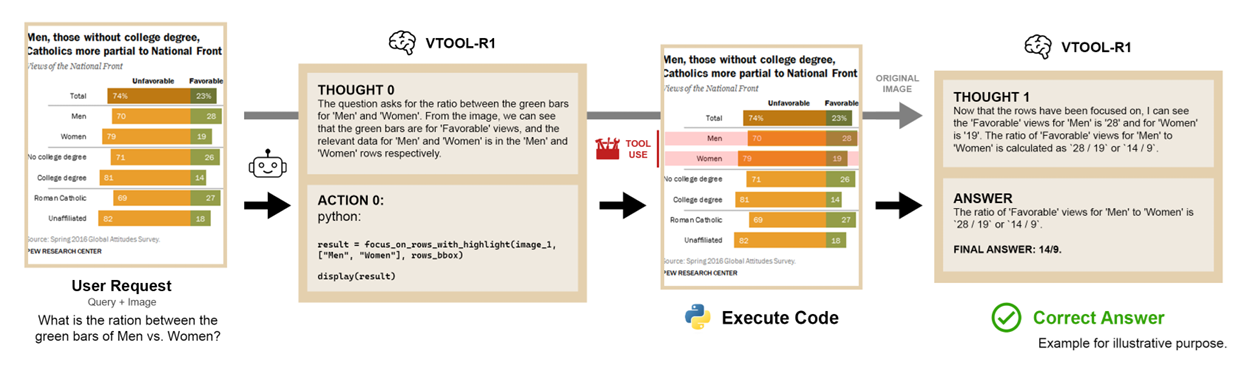 |
VTool-R1: VLMs Learn to Think with Images via Reinforcement Learning on Multimodal Tool Use
ICLR 2026 |
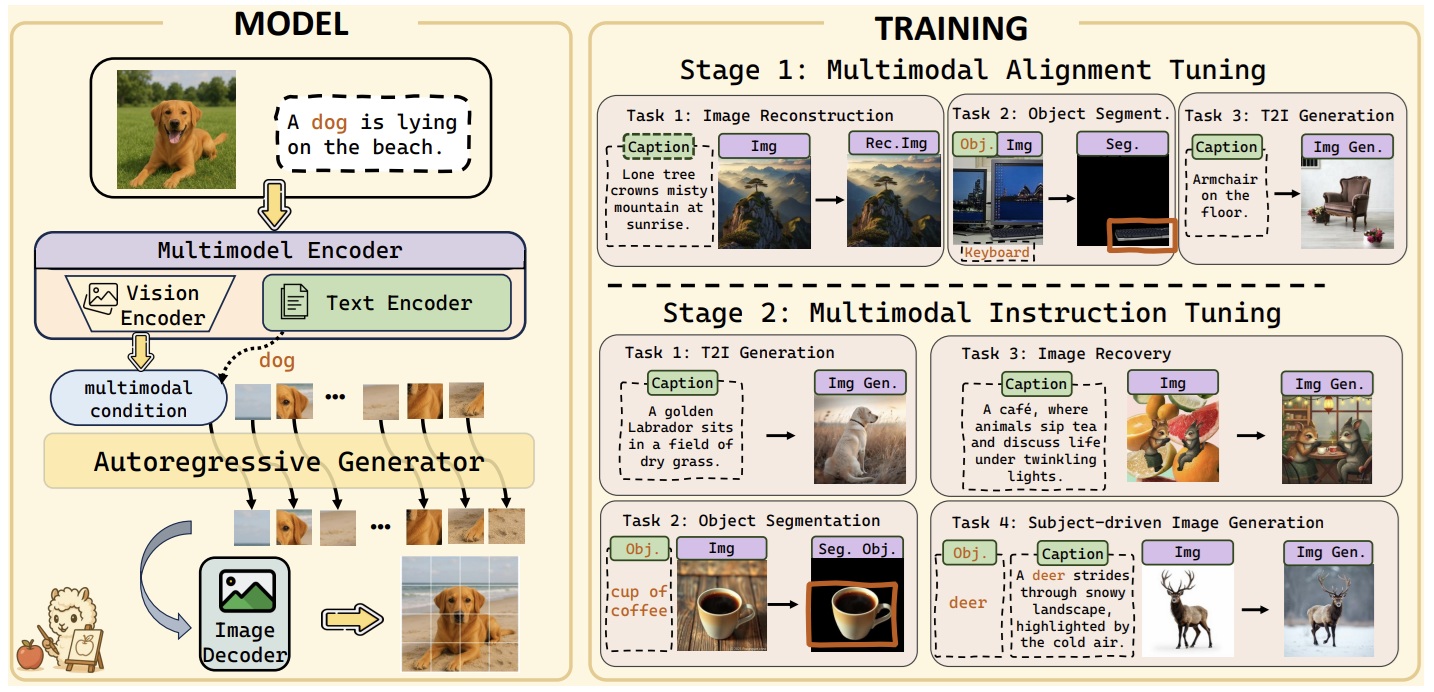 |
MENTOR: Efficient Autoregressive Image Generation with Balanced Multimodal Control
ACL Findings 2026 |
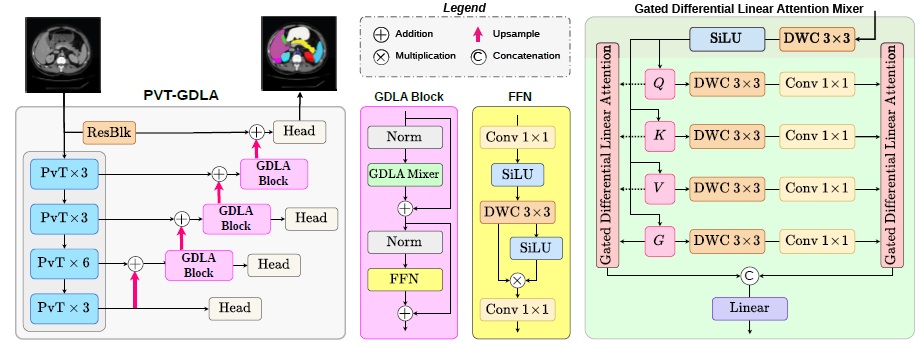 |
Gated Differential Linear Attention: A Linear-Time Decoder for High-Fidelity Medical Segmentation
CVPR Findings 2026 |
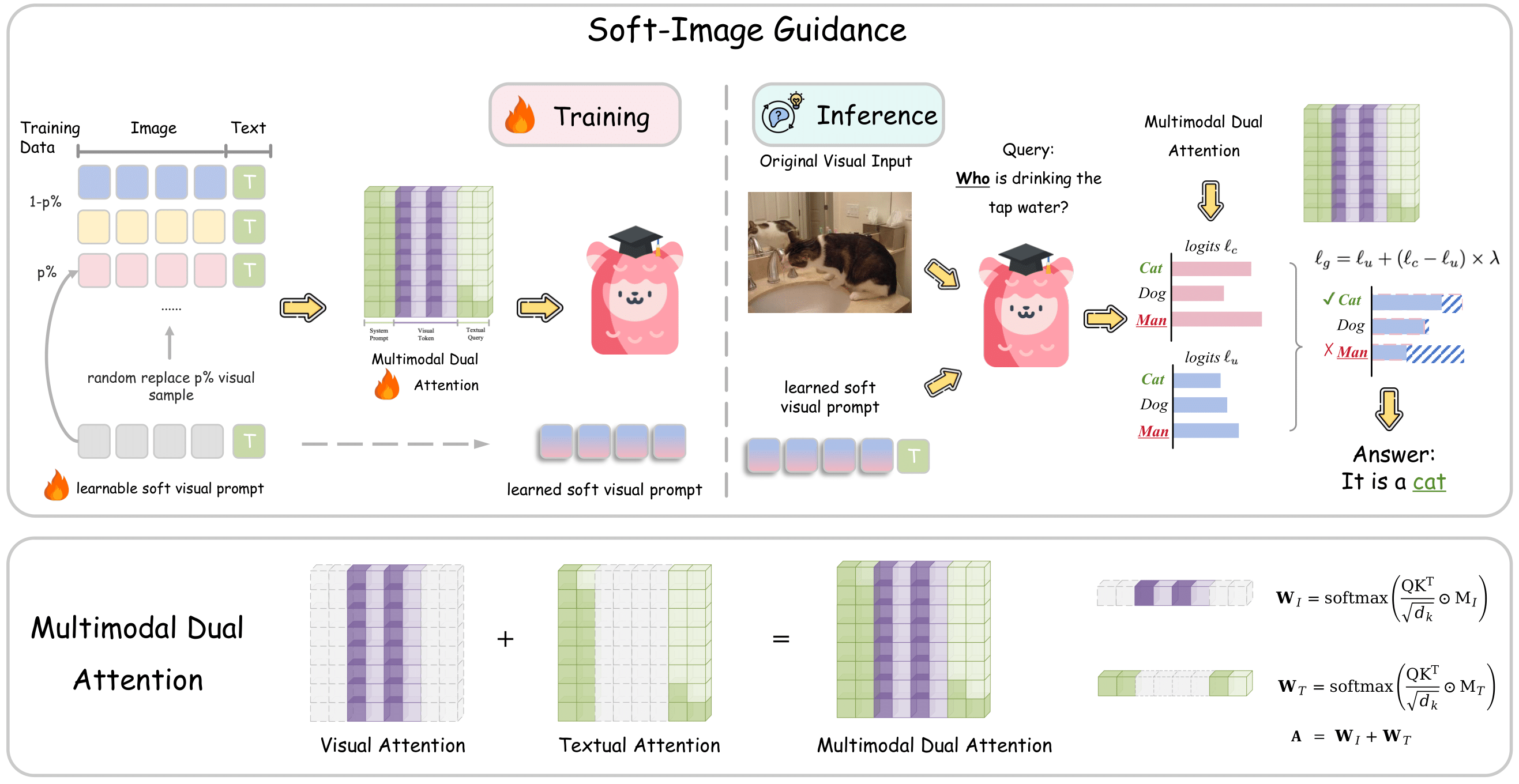 |
EMNLP 2025 [Project Page] |
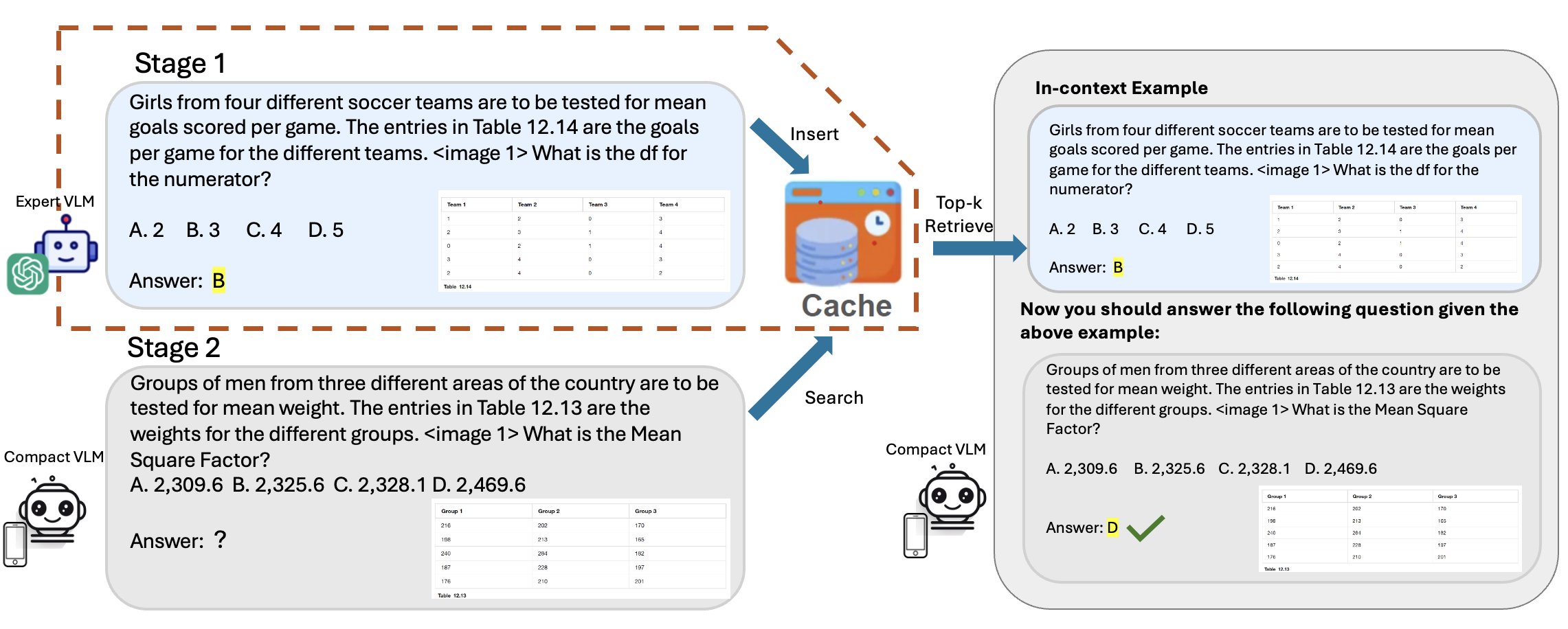 |
Cache-of-Thought: Master-Apprentice Framework for Cost-Effective Vision Language Model Inference
EMNLP 2025 |
 |
NeurIPS (MAR) 2025 |
 |
InstantEdit: Text-Guided Few-Step Image Editing with Piecewise Rectified Flow
ICCV 2025 [Project Page] |
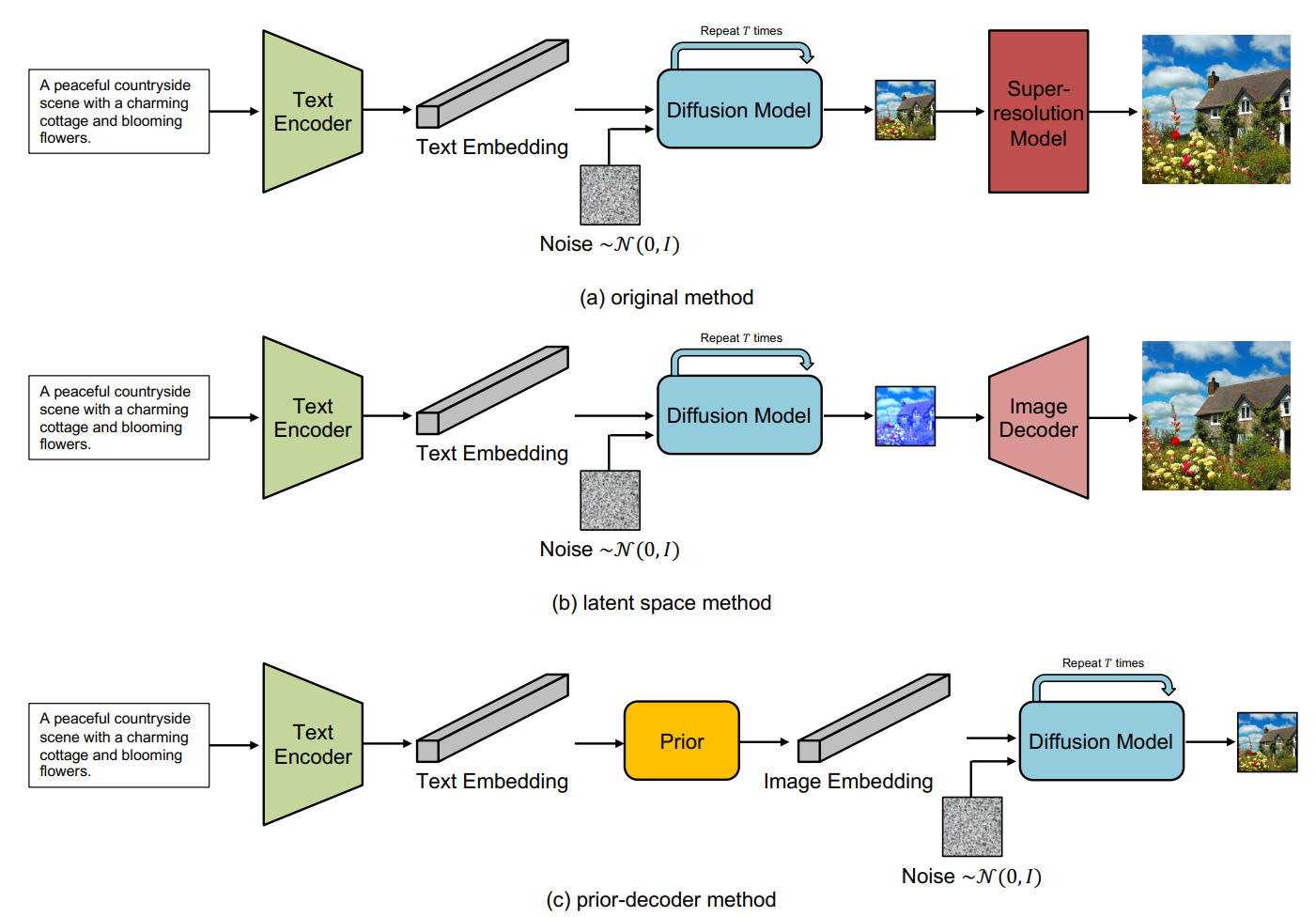 |
RenAIssance: A Survey into AI Text-to-Image Generation in the Era of Large Model
IEEE Transactions on Pattern Analysis and Machine Intelligence 2025 |
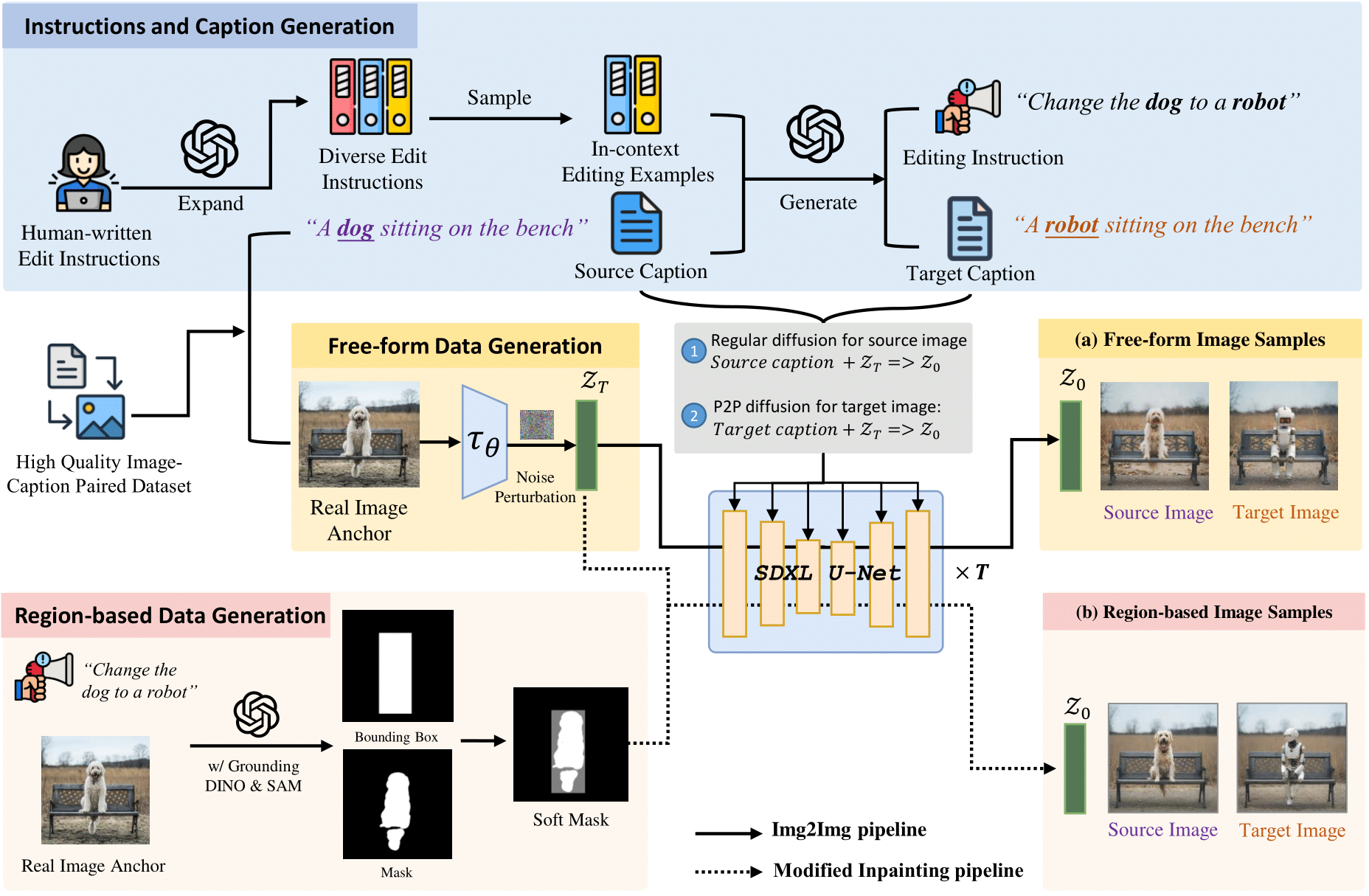 |
UltraEdit: Instruction-based Fine-Grained Image Editing at Scale
NeurIPS 2024 D&B [Project Page (w. Demo)] |
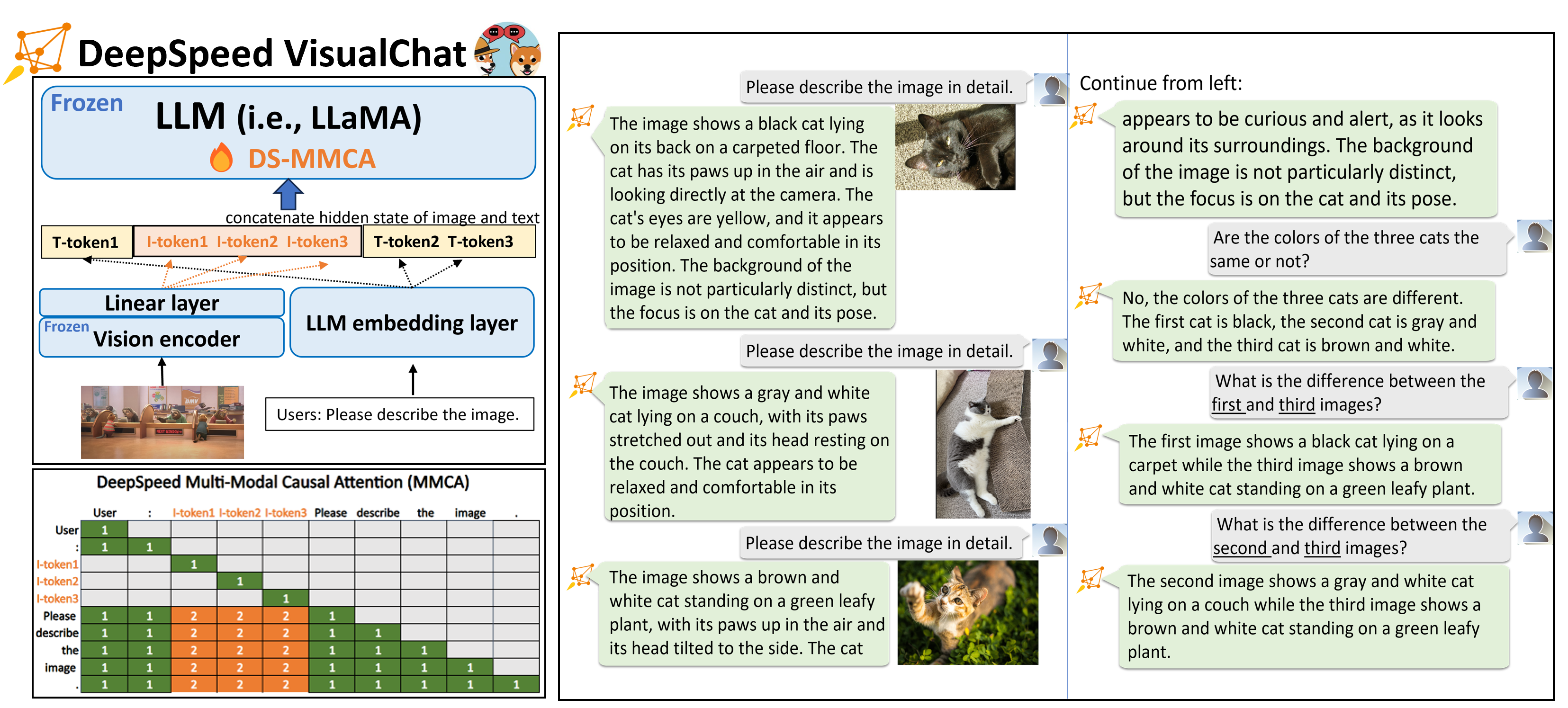 |
DeepSpeed-VisualChat: Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention
Preprint |
High-Performance Vector Database Systems Built for Speed and Scale
|
VecFlow: A High-Performance Vector Data Management System for Filtered-Search on GPUs
SIGMOD 2026 [Project Page] The first GPU-accelerated filter-based vector search system, delivering up to 100X higher throughput than state-of-the-arts CPU-based solutions! VecFlow received a mention in NVIDIA's GTC 2025 talk on GPU-accelerated vector search. |
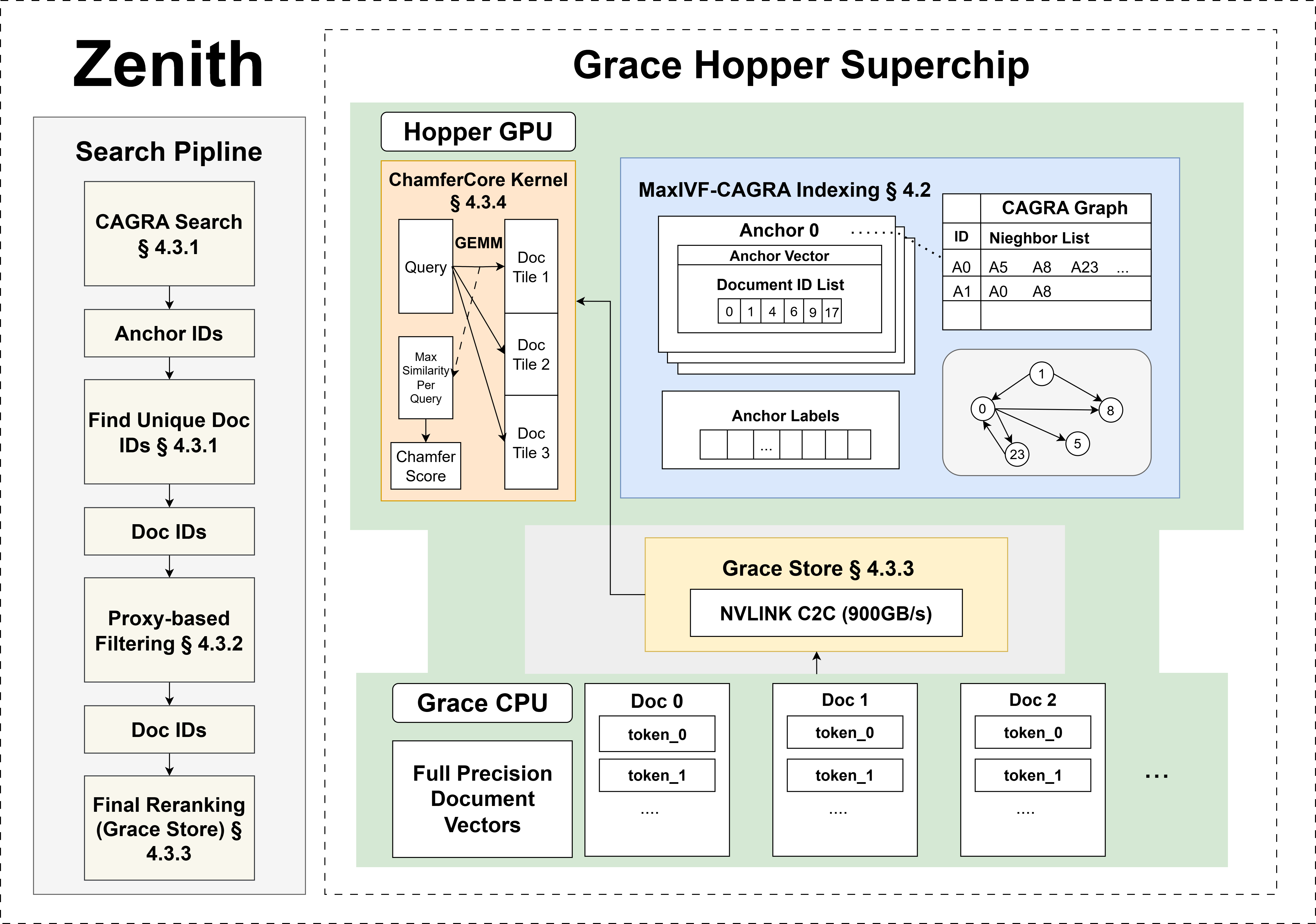 |
SIGMOD 2026 [Project Page] High-performance multi-vector search system, delivering up to 10x higher throughput than state-of-the-arts solutions! |
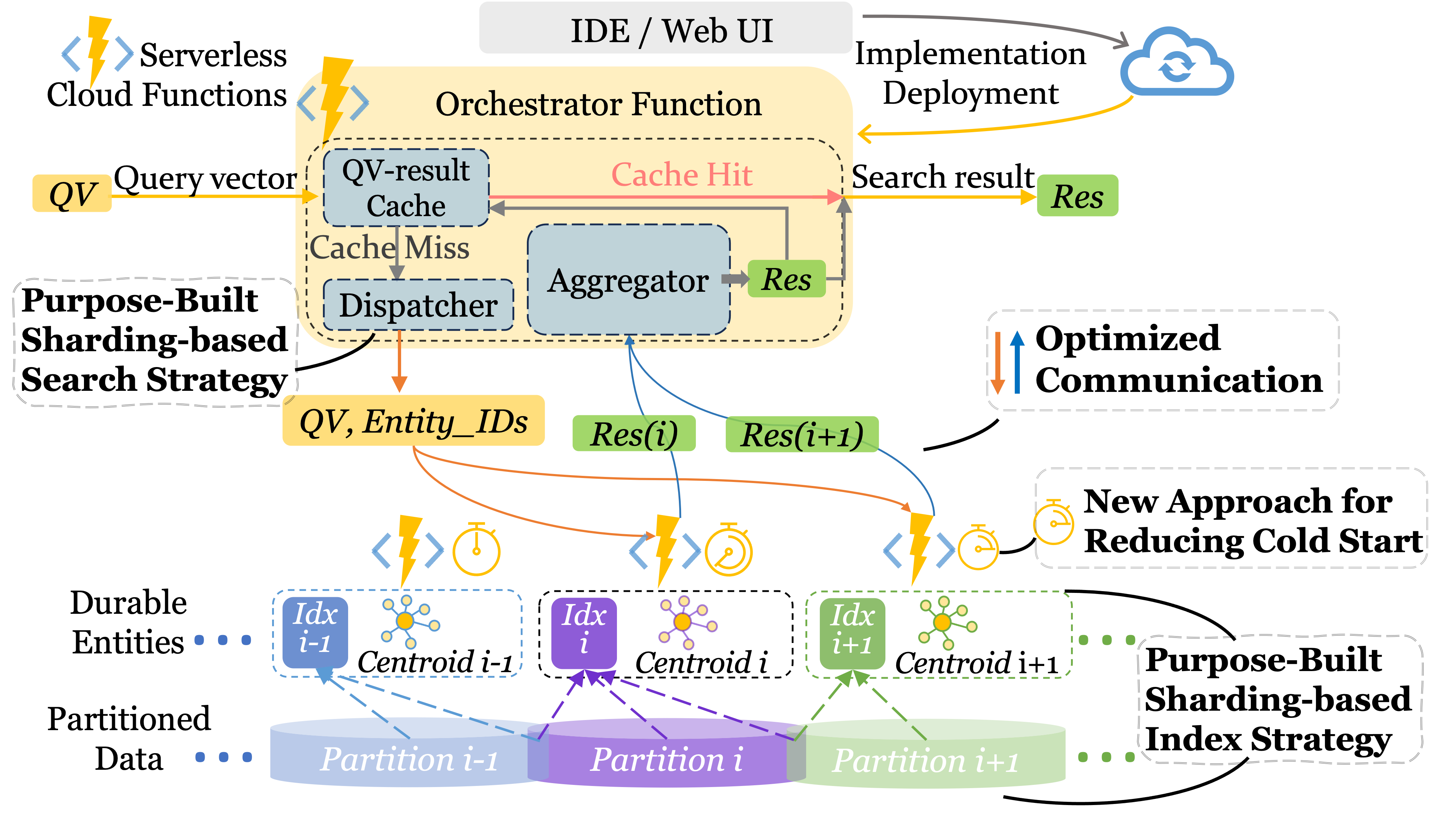 |
Vexless: A Serverless Vector Data Management System Using Cloud Functions
SIGMOD 2024 |
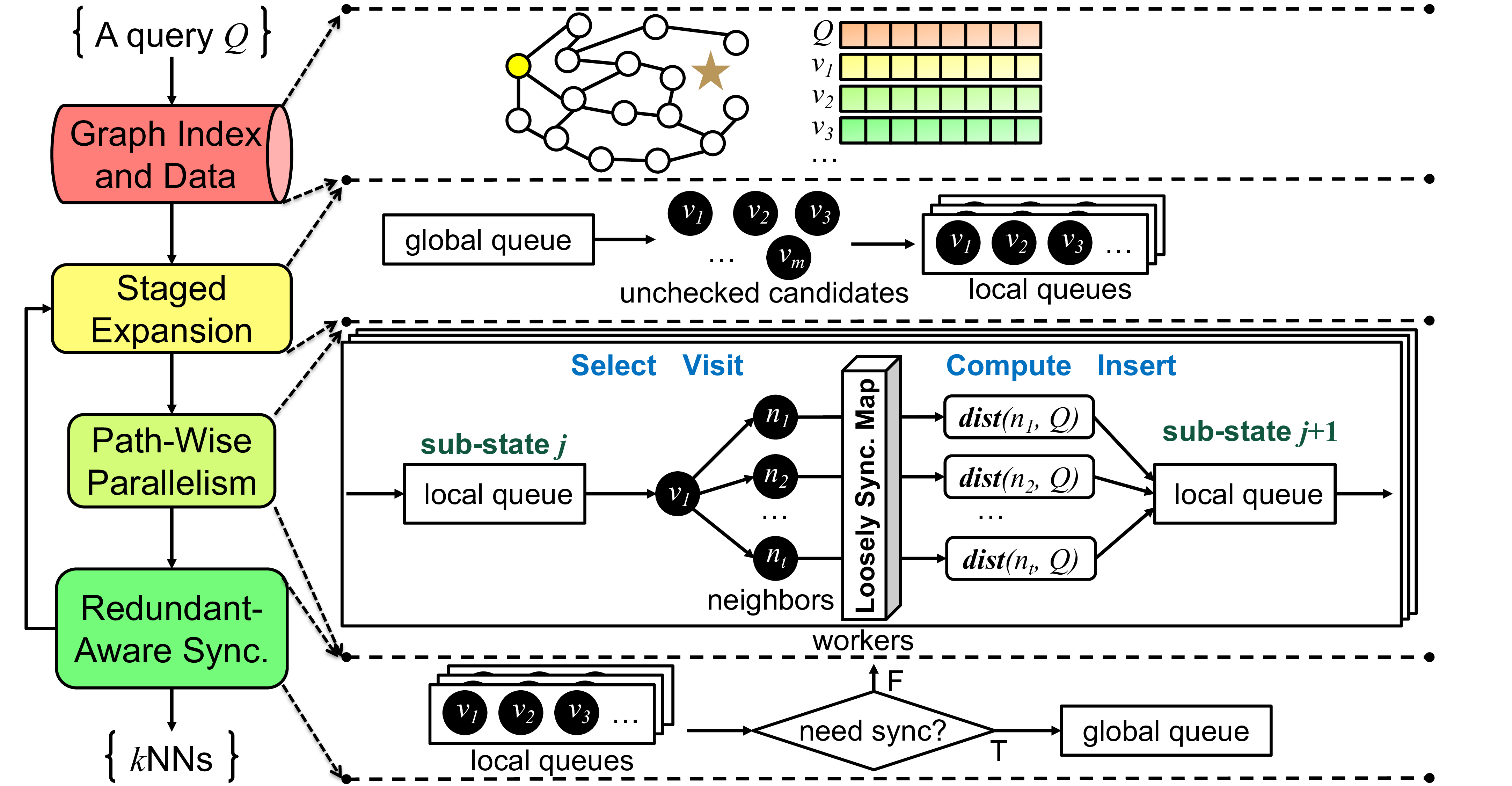 |
PPoPP 2023 |
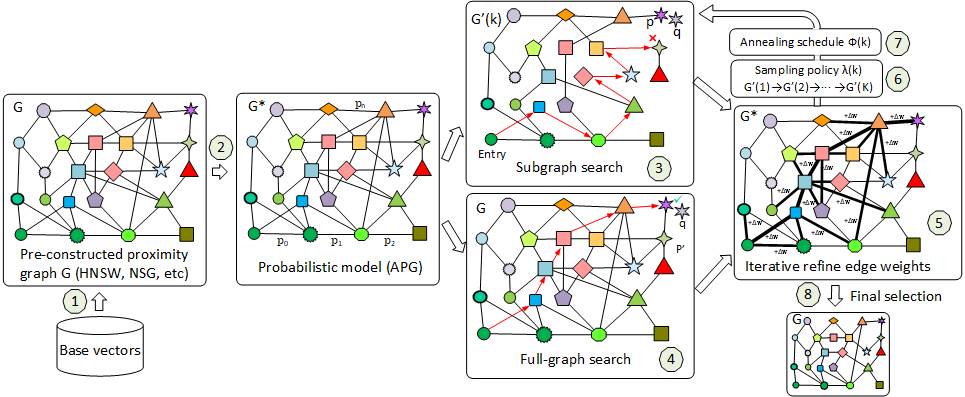 |
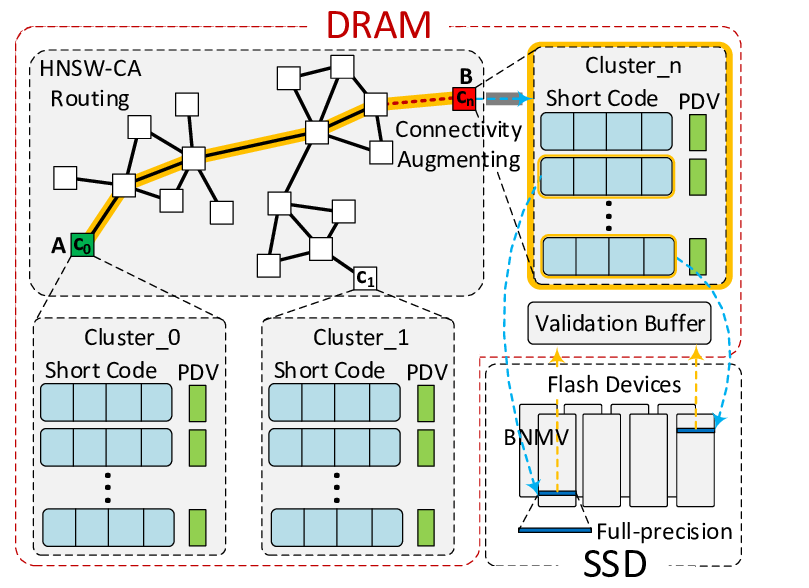
GraSP: Optimizing Graph-based Nearest Neighbor Search with Subgraph Sampling and Pruning
WSDM 2022 |
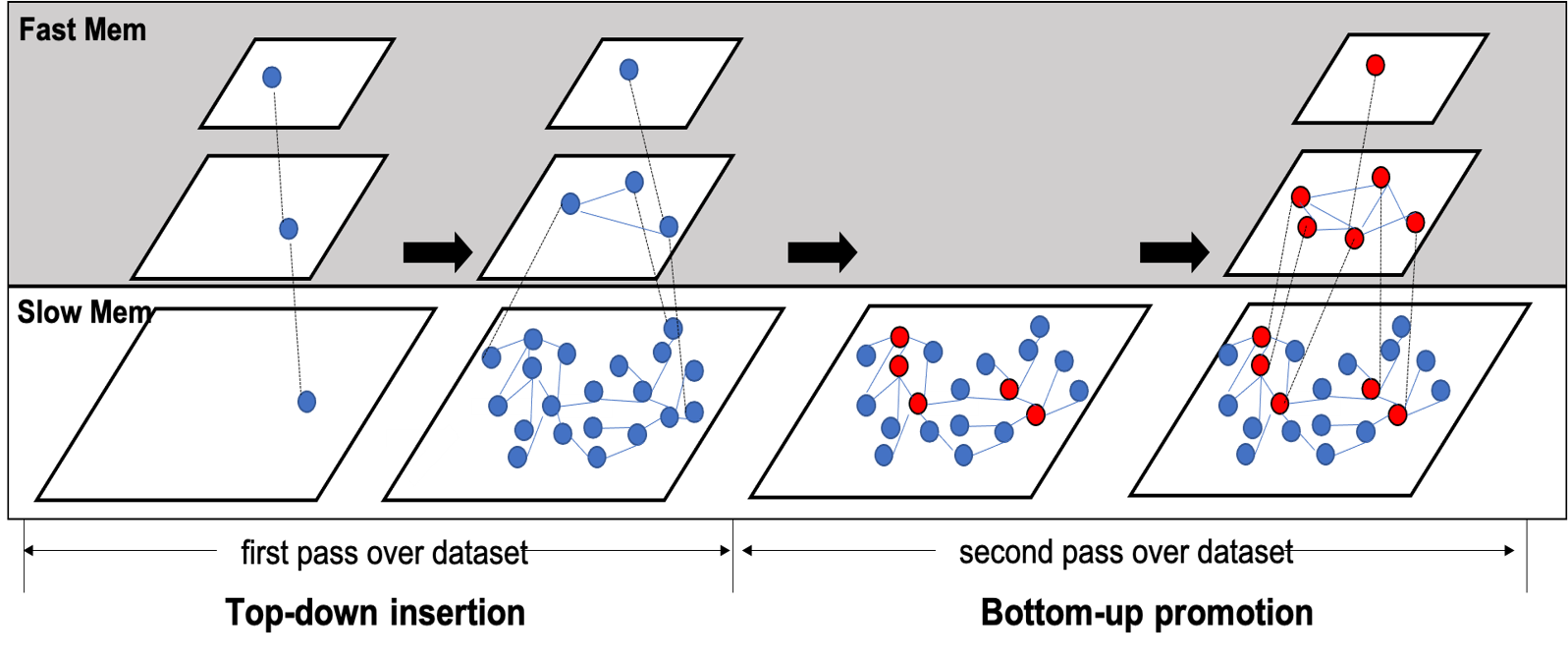 |
HM-ANN: Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory
NeurIPS 2020 |
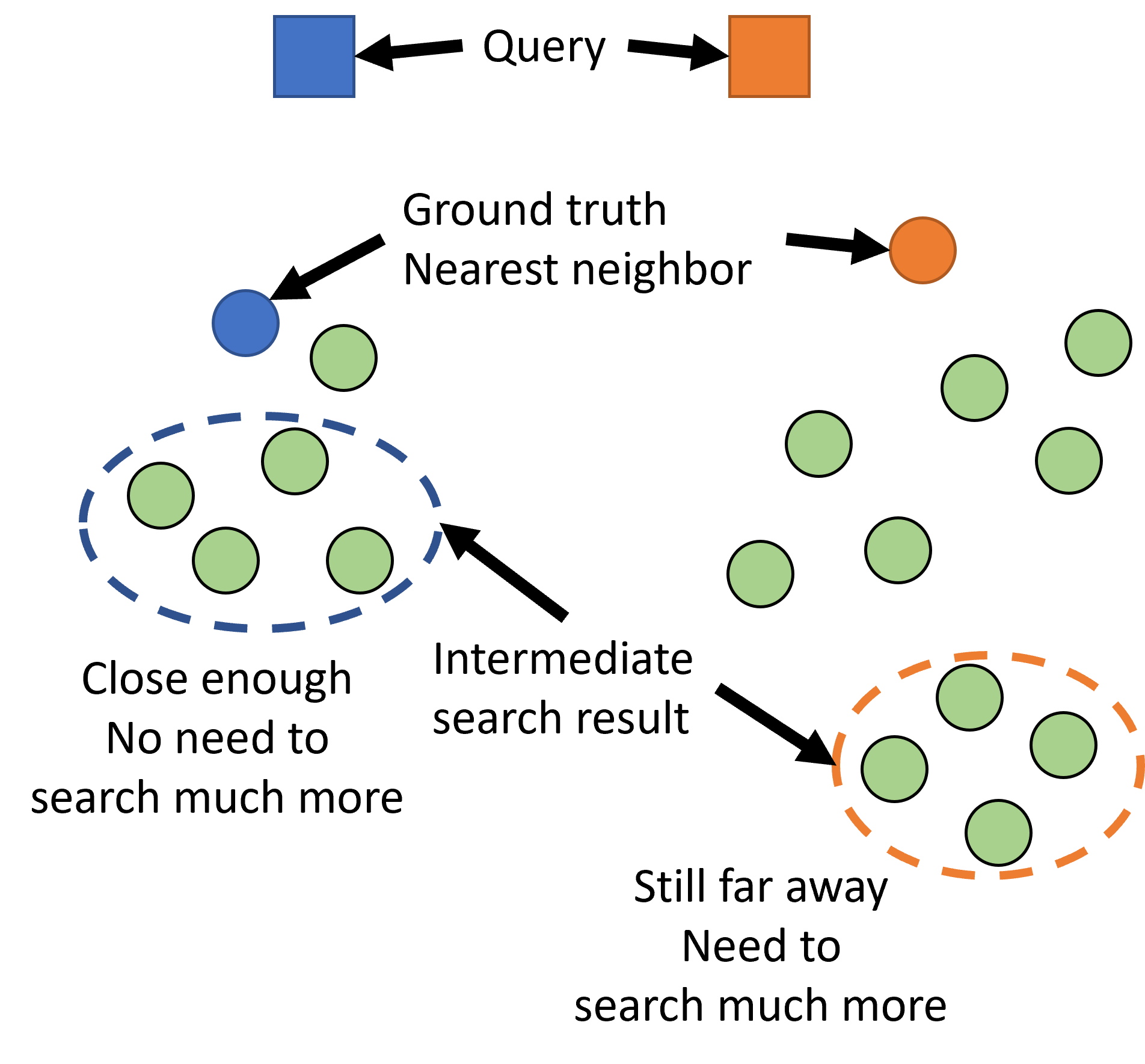 |
Improving Approximate Nearest Neighbor Search through Learned Adaptive Early Termination
SIGMOD 2020 |
 |
CIKM 2019 |
Parallel Computing and Scalable Runtime
- TOPC 2017 "Hybridizing and Relaxing Dependence Tracking for Efficient Parallel Runtime Support", Man Cao, Minjia Zhang, Aritra Sengupta, Swarnendu Biswas, and Michael D. Bond, In ACM Transactions on Parallel Computing.
- ISMM 2017 "Avoiding Consistency Exceptions Under Strong Memory Consistency Models", Minjia Zhang, Swarnendu Biswas, Michael D. Bond, in the 2017 ACM SIGPLAN International Symposium on Memory Management.
- CC 2017 "Lightweight Data Race Detection for Production Runs", Swarnendu Biswas, Man Cao, Minjia Zhang, Michael D. Bond, and Benjamin P. Wood, in the 26th International Conference on Compiler Construction.
- PPoPP 2017 "On the Problem of Consistency Exceptions in the Context of Strong Memory Models", Minjia Zhang, Swarnendu Biswas, Michael D. Bond, in the 22th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming.
- CC 2016 "Relaxed Dependence Tracking for Parallel Runtime Support", Minjia Zhang, Swarnendu Biswas, Michael D. Bond, in the 25th International Conference on Compiler Construction.
- PPoPP 2016 "Drinking from Both Glasses: Combining Pessimistic and Optimistic Tracking of Cross-Thread Dependences", Man Cao, Minjia Zhang, Aritra Sengupta, and Michael Bond, in the 21th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming.
- OOPSLA 2015 "Valor: Efficient, Software-Only Region Conflict Exceptions"(Distinguished Artifact Award, Distinguished Paper Award), Swarnendu Biswas, Minjia Zhang, Michael D. Bond, and Brandon Lucia, in the 2015 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications.
- PPoPP 2015 "Low-Overhead Software Transactional Memory with Progress Guarantees and Strong Semantics", Minjia Zhang, Jipeng Huang, Man Cao, and Michael D. Bond, in the 20th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming.
- ASPLOS 2015 "Hybrid Static-Dynamic Analysis for Statically Bounded Region Serializability", Aritra Sengupta, Swarnendu Biswas, Minjia Zhang, Michael D. Bond, and Milind Kulkarni, in the 20th International Conference on Architectural Support for Programming Languages and Operating Systems.
- SPLASH 2015 Companion "SIRe: An Efficient Snapshot Isolation based Memory Model for Detecting and Tolerating Region Conflicts", Minjia Zhang, in 2015 ACM SIGPLAN International Conference on Systems, Programming, Languages and Applications: Software for Humanity.
- WoDet 2014 "Drinking from Both Glasses: Adaptively Combining Pessimistic and Optimistic Synchronization for Efficient Parallel Runtime Support", Man Cao, Minjia Zhang, and Michael D. Bond, in the 5th Workshop on Determinism and Correctness in Parallel Programming.
- OOPSLA 2013 "Octet: Capturing and Controlling Cross-Thread Dependences Efficiently", Michael D. Bond, Milind Kulkarni, Man Cao, Minjia Zhang, Meisam Fathi Salmi, Swarnendu Biswas, Aritra Sengupta, and Jipeng Huang, in the 2013 ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications.
- ICPP 2011 "Memcached Design on High Performance RDMA Capable Interconnects", J. Jose, H. Subramoni, M. Luo, M. Zhang, J. Huang, M. W. Rahman, N. S. Islam, X. Ouyang, S. Sur and D. K. Panda, in the 40th International Conference on Parallel Processing.
- ICPADS 2010 "VirtCFT: A Transparent VM-level Fault-Tolerant System for Virtual Clusters", Minjia Zhang,Hai Jin,Song Wu,Xuanhua Shi, in IEEE 16th International Conference on Parallel and Distributed Systems.
Selected Awards and Honors
- 🏆 UIUC Dean's Award for Excellence in Research, 2026
- 🏆 Amazon Research Award, 2025
- 🏆 Google ML and Systems Junior Faculty Award, 2025
- 🏆 NSF ACCESS Maximize Award, 2025
- 🏆 NSF CAREER Award, 2025
- 🏆 AMD AI & HPC Award, 2024
- 🏅 Honorable Mention of Best Paper Award, ASPLOS 2026
- 🏅 Best Student Paper Award, SC 2025
- 🏅 Honorable Mention of Outstanding Paper Awards, ICLR 2024
- 🏅 Distinguished Paper Award, OOPSLA 2015
- 🏅 Distinguished Artifact Award, OOPSLA 2015
- 👨🎓 Supervised student recipient of Microsoft Research Fellowship, 2026
- 👨🎓 Teachers Ranked as Excellent by Their Students, UIUC Spring 2025 (inaugural CS 498: Machine Learning Systems)
- 👨🎓 Supervised student recipient of Amazon PhD Fellowship, 2025
- 💡 Microsoft Excellence Award, 2017
- 💡 Selected by Microsoft CTO Kevin Scott for "Cool Tech" showcase (DeepCPU), 2017
Patents
- Minjia Zhang, Yuxiong He, "Multi-Layer Semantic Search", U.S. Patent, MS# 406007-US-NP, 2019
- Minjia Zhang, Xiaodong Liu, Wenhan Wang, Jianfeng Gao, Yuxiong He, “Graph Representations for Identifying a Next Word”, US 2019 / 0377792 A1
- Minjia Zhang, Samyam Rajbhandari, Wenhan Wang, Yuxiong He, “Deep Learning Model Scheduling”, US 2019 / 0311245 A1
- Invited talk on ``MegaFold: System-Level Optimizations for Accelerating Protein Structure Prediction Models" by AMD, August 14 2025.
- Invited talk on ``System-Level Optimizations for Accelerating Protein Structure Prediction Models" by the Trillion Parameter Consortium (TPC'25), July 31 2025.
- Invited talk on ``Towards Efficient and Scalable Systems for Training Large-Scale AI-based Scientific Models" by Deming Chen at AMD-Xilinx Heterogeneous Compute Cluster (HACC) Seminar, February 12th 2025.
- Invited lecture on ``Mixture-of-Experts in the Era of LLMs" by Arvind Krishnamurthy at University of Washington, November 28th 2024.
- Invited talk on ``Efficient and Scalable Machine Learning Systems for Training Large-Scale DL Models on Parallel and Distributed Hardware" at Meta Monetization AI Speaker Series, September 25th 2024.
- Tutorial and panel speaker at "Mixture-of-Experts in the Era of LLMs: A New Odyssey" at ICML'2024
- Invited talk on "Towards Efficient System and Algorithm for Large-Scale Scientific Discovery" at the European Trillion Parameter Consortium (TPC) Kickoff workshop in Barcelona in June 2024
- Invited panel speaker at the Efficient Natural Language and Speech Processing (ENLSP-III) workshop at NeurIPS 2023
- Presented work on "Efficient System and Algorithm Design for Deep Learning Training and Inference", University of Illinois at Urbana-Champaign, Purdue University, University of Virginia, University of Minnesota, Indiana University Bloomington, Colorado School of Mines, Stevens Institute of Technology
- Presented work on "XTC: Extreme model compression made simple and efficient" at NeurIPS 2022
- Invited talk on "Extreme Compression for Pre-trained Transformers Made Simple and Efficient" at Intel AI Group, July 28th 2022
- Invited talk by Zhihao Jia on "DeepSpeed: The library to accelerate training and inference of DNN at scale" at CMU, April 18th 2022
- Invited talk on "DeepSpeed: The library to accelerate training and inference of DNN at scale" at the Efficient Large-Scale AI Workshop as a part of MSR Project Green
- Invited talk by Myeongjae Jeon on "DeepSpeed: The library to accelerate training and inference of DNN at scale" at UNIST, April 13th 2022
- Invited lecture on "New algorithms for Approximate Nearest Neighbor Search Systems at Scale" at Kent State University, October 20, 2022
- Presented work on graph sampling and pruning for nearest neighbor search at WSDM 2022
- Invited talk on "DL Inference and Training Optimization Towards Speed and Scale" at Tsinghua AIR 2021
- Invited keynote speech on "DL Inference and Training Optimization Towards Speed and Scale" at EMDC 2021
- Presented work on DL inference through heterogeneous devices at IPDPS 2021
- Presented work on "DynaTune: Dynamic Tensor Program Optimization in Deep Neural Network Compilation" at ICLR 2021
- Invited keynote speech on "DL Inference and Training Optimization Towards Speed and Scale" at EMDC 2021
- Presented work on "Accelerating Training of Transformer-Based Language Models with Progressive Layer Dropping" at NeurIPS 2020
- Presented work on "AdaTune: Adaptive Tensor Program Compilation Made Efficient" at NeurIPS 2020
- Invited talk on "TVM@Microsoft" at the TVM and Deep Learning Compilation Conference 2019, Seattle, Washington, US
- Presented work on "GRIP: Multi-Store Capacity-Optimized High-Performance Nearest Neighbor Search for Vector Search Engine" at CIKM 2019, Beijing, China
- Presented work on "Accelerating Large Scale Deep Learning Inference through DeepCPU at Microsoft" at 2019 USENIX OpML, May 2019, Santa Clara, CA, USA
- Presented work on "DeepCPU: Serving RNN-based Deep Learning Models 10x Faster" at 2018 USENIX Annual Technical Conference, July 2018, Boston, MA, USA
- Invited talk on "DeepCPU: Deep Learning Serving Optimizations on CPUs" at the Deep Learning workshop at Microsoft TechFest 2018, March 2018, Redmond, WA, USA
- Invited talk on "DeepCPU: Deep Learning Serving Optimizations on CPUs" at Microsoft Research Talk Series, February 2018, Redmond, WA, USA
- Presented work on "DeepCPU: Deep Learning Serving Optimizations on CPUs" at Machine Learning, AI & Data Science Conference (MLADS) December 2017, Redmond, WA, USA
- Presented work on detecting and tolerating region conflicts to support region snapshot isolation at ACM Student Research Competition, OOPSLA 2015, Pittsburg, PA, USA
- Presented work on low-overhead and scalable software transactional memory with strong progress guarantees at the 20th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPoPP 2015, San Francisco, CA, USA
Talks
Professional Service and Membership
- Editorial Service :
- Associate Editor, ACM Computing Surveys (CSUR), ACM, 2026-Present
- Organizer:
- Organizer of ASPLOS 2026 Tutorial: "Building Efficient Large-Scale Model Systems with DeepSpeed: From Open-Source Foundations to Emerging Research"
- Organizer of ICML'24 Tutorial: "Mixture-of-Experts in the Era of LLMs: A New Odyssey"
- Area/Session Chair: AAAI 2027 Senior Program Committee, ICLR 2026 Area Chair, HPCA 2026 Sponsorship Chair, APSys 2025 Publicity Chair, PPoPP 2025 Session Chair, NeurIPS 2024 Area Chair, ASPLOS 2019 Machine Learning Track Session Chair, Publicity Co-Chair of PLDI 2019
- Program Committee: HPCA 2027, ACM MM 2026, ICPP 2026, ICDCS 2026, PACMI 2025, USENIX ATC 2025, PPoPP 2025, AAAI 2025, USENIX ATC 2024, MLSys 2024, ASPLOS 2023, ICDE 2023 Industry and Applications Track, MLSys 2023, IPDPS 2023, IPDPS 2021, IPDPS 2020, IPDPS 2019, IPDPS 2018, ASPLOS 2018 Shadow PC, PLDI 2017 Artifact Evaluation, SPLASH 2015 Artifact Evaluation, PLDI 2015 Artifact Evaluation
- Conference Reviewer: ICML 2026 (Gold Reviewer), VLDB 2024, ECCV 2024, ICML 2024, ICLR 2024, CVPR 2024, AAAI 2024, ICLR 2023, AAAI 2023, CVPR 2023, ICCV 2023, ECAI 2023, ICLR 2022, AAAI 2022, CVPR 2022, USENIX ATC 2022, ICML 2022, ECCV 2022, NeurIPS 2022, ASPLOS 2021, AAAI 2021, ICLR 2021, CVPR 2021, ICCV 2021, ICML 2021, NeurIPS 2021, NeurIPS 2020, ICLR 2020, NeurIPS 2019, NeurIPS 2019 Reproducibility Challenge, PLDI 2019, ASPLOS 2019, Middleware 2018 subreviewer, ICAC 2018 subreviewer, IEEE Cloud 2018 subreviewer, HiPC 2017 subreviewer, ICAC 2017 subreviewer, WTTM 2015 subreviewer.
- Journal Reviewer: ACM Transactions on Database Systems (2024), Transactions on Machine Learning Research (2022-2023), Journal of Systems and Software (2020), IEEE Transaction on Cloud Computing (2019-2020), ACM Transaction on Privacy and Security (2019), Journal of Computer Science (2017-2018), Concurrency and Computation: Practice and Experience (2016-2017)
- Membership:
- ACM member
- IEEE member
- SIGOPS member
- SIGHPC member
- Sigma Xi member
Past and Current Collaborators











